

Authors: Yuansheng Wang, Apache APISIX PMC member, Apache member, Co-founder & CTO of API7.ai, and author of Apache APISIX in Action. This article is based on Yuansheng's presentation at the APISIX Shenzhen Meetup on April 12, 2025.
The Focus of the AI Era — Why
In 2015, I co-founded the open-source project APISIX with Ming Wen, and in 2019, we donated APISIX to the Apache Software Foundation. Over the past six years, from my personal perspective, its achievements have been remarkable. Initially, our goal was simple: to create an API gateway that could be used by others. However, as time went on, users from various fields began to adopt APISIX, such as Geely Automobile and Honor Mobile. When these products use APISIX to serve me, it feels like a child I created is giving back to its parents. This positive cycle is truly inspiring.
In the past two to three years, the rapid pace of technological development has been continuously changing our world. Initially, I thought I had little to do with AI development. However, after personally using AI, I found it to be extremely helpful. Now, in our daily work, we almost can't do without AI. However, the most challenging part of using AI is asking the right questions.
AI is essentially an empowering tool that can assist everyone, but the effectiveness of this assistance depends on the users. For example, if you have a high level of expertise, say 100 points, AI might help you improve to 120 points. But if you only have 50 points, it might only help you reach 60 points. Why is that? Because AI itself is static and can only serve as an auxiliary tool to humans. Different users will get different results when using it.
In the AI era, the most challenging part is asking the right questions. Meanwhile, to enhance one's position in society, the Golden Circle principle (Why, How, What) becomes crucial. Upon deeper reflection, we find that asking questions and the Golden Circle principle have significant overlap. The core of both lies in addressing the essential Why, rather than just focusing on the superficial What. Only by asking complete questions can we obtain the correct answers.
Introduction to Apache APISIX
API7.ai is the original creator and donator of Apache APISIX. Currently, it takes the loin's share in the Chinese API management market. We serve over 300,000 services and process more than ten trillion requests daily. APISIX has the following features:
- Fully dynamic, real-time, and high-performance
- high security and stability
- Its cloud-native architecture provides strong elasticity and scalability, making it well-adapted to modern cloud environments
- Offer flexibility in hot reloading
- Rich ecosystem, integrating with various technologies and tools
- Active community ensures continuous contributions from numerous developers and users to the project's development
For these reasons, APISIX is suitable for various scenarios, including enterprise north-south traffic gateways, east-west traffic application API gateways, Kubernetes Ingress Controllers, and service meshes. APISIX's applications have permeated almost every aspect of our daily lives. Whether you're hailing a taxi, calling an electric vehicle, conducting voice office work, making video calls, or trading stocks, APISIX is quietly providing support behind the scenes. Even fast-food chains like McDonald's and KFC, as well as virtually all domestic mobile phone and electric vehicle manufacturers, and even power bank providers, have APISIX's presence.

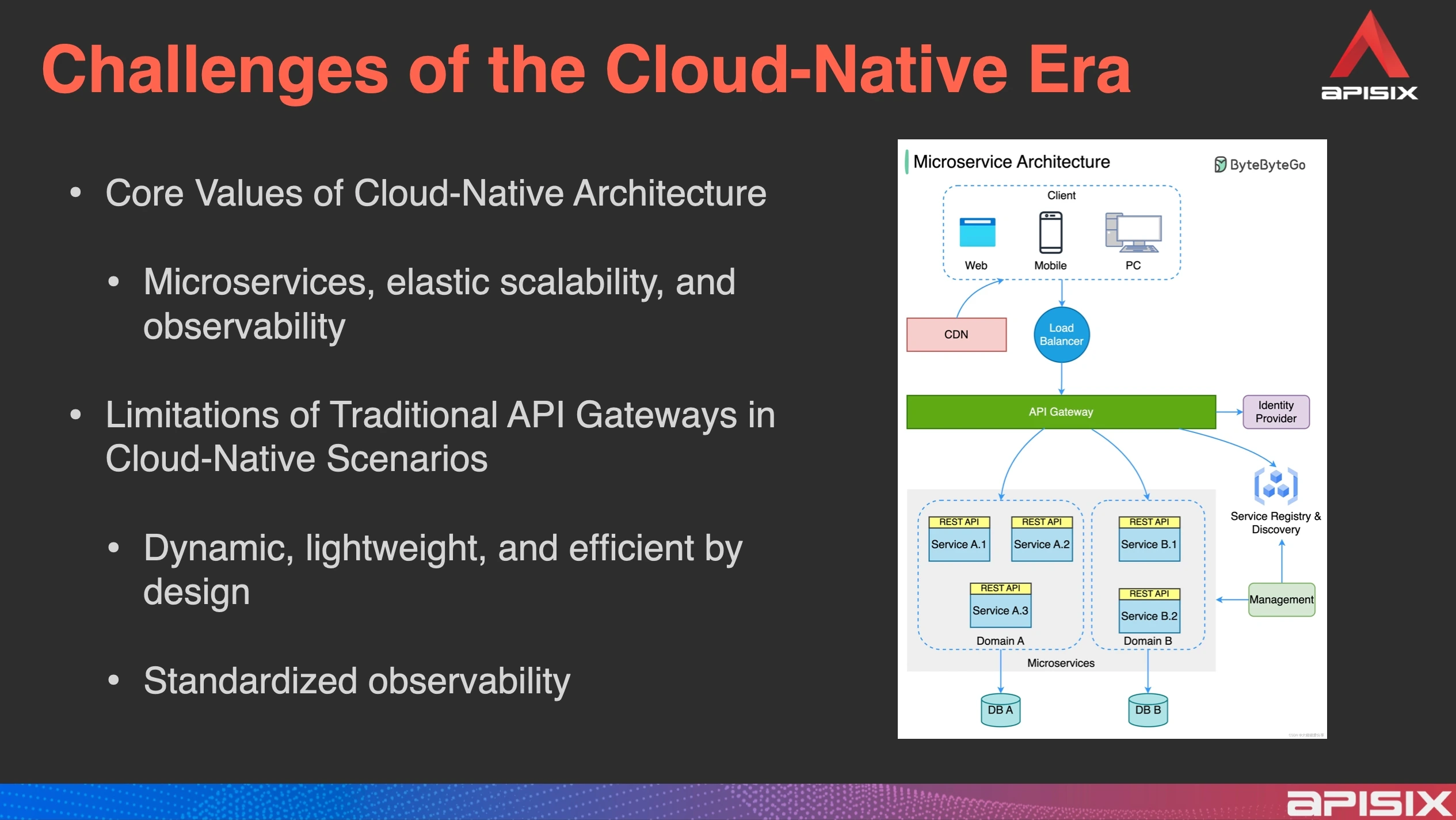
Technical Evolution: From Cloud-Native to AI-Native
Cloud-native refers to systems can be elastically scaled to efficiently and swiftly respond to dynamically changing business demands. AI-native builds upon this architecture, emphasizing the support for proxying AI model requests, particularly in conversational application scenarios. Although these requests still use the HTTP protocol, consistent with traditional service requests, they exhibit significant differences in performance.
Specifically, AI request responses are typically slower. For instance, when a user poses a question to AI, the response time is often slower than traditional HTTP requests. In general, traditional HTTP requests usually have response times ranging from 10 to 100 milliseconds, with slightly longer ones completing within a few hundred milliseconds, essentially finishing interactions within one second. However, due to the generative computing nature of AI requests, response times are significantly prolonged.
Furthermore, AI applications introduce new security challenges. Taking internal corporate data as an example, in the past, people were most concerned about issues like Samsung's sensitive document leaks. In traditional business scenarios, enterprises rarely submit complete documents to external services, a process usually subject to strict and cautious evaluation. However, such operations are common in AI applications. For example, during rental or home purchasing processes, users may submit contract documents to AI models to analyze potential legal risks. Consequently, AI applications have triggered new internal information security requirements.
Finally, when selecting AI services, enterprises must also consider cost comprehensively. Taking ChatGPT and DeepSeek as examples, although they have similar functional capabilities, DeepSeek is significantly more cost-effective. Enterprises need to balance investments and returns in terms of response speed, output quality, cost control, system stability, and reliability.
The Rise of AI and APISIX's Response
Against the backdrop of the rise of AI applications, AI traffic characteristics differ significantly from traditional traffic. As a high-performance and highly scalable API gateway, APISIX can theoretically proxy all types of HTTP requests without technical obstacles. However, to proxy AI requests, additional performance and feature requirements must be met to accommodate the unique needs of AI services.
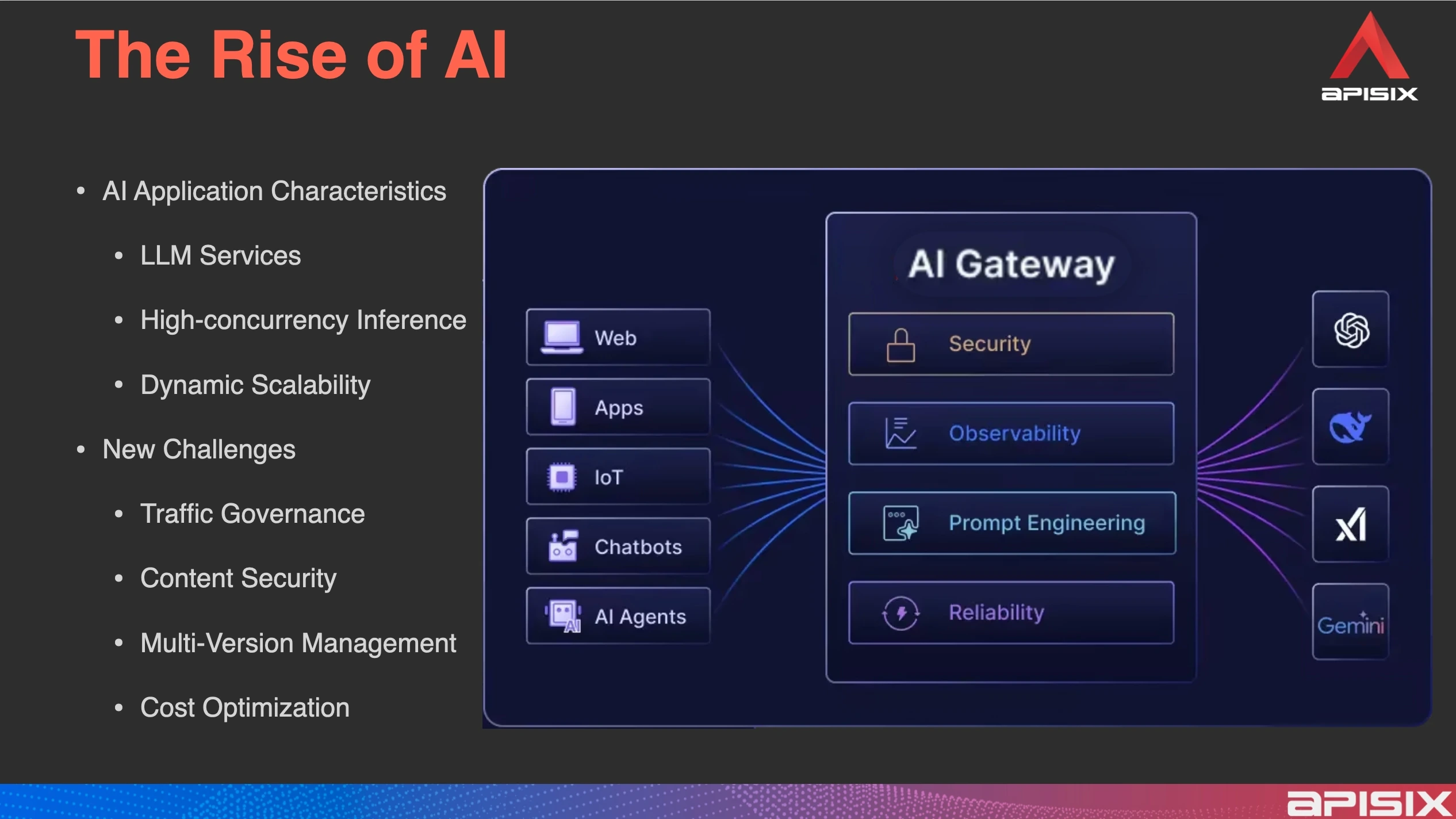
Whether for commercial or open-source users, in the context of enterprise-level AI service usage, selecting an AI gateway has become a necessary prerequisite. The reason enterprises need to deploy an AI gateway is that when using AI services—whether from public clouds or private large model instances—they must achieve unified access control, security auditing, and cost management.
Some may question: If one is simply making simple calls through public services like ChatGPT, is it still necessary to deploy an AI gateway? The answer is yes. Take the confidential information leak incident at Samsung as an example. One of the root causes was the lack of a unified mechanism for recording content submission and response processes. An AI gateway can provide a unified entry point for content transmission within enterprises, ensuring all requests and responses are traceable and auditable, thereby safeguarding data security.
During the use of AI services, enterprises should centralize the recording of content submission and responses at the company level. Additionally, if there are uncontrollable factors in costs, corresponding recording mechanisms should be established. These measures fall under the scope of unified company-level security auditing and cost control.
Traditional enterprises might think that purchasing a user account allows direct use of AI services without the need to build any internal infrastructure. However, this is not the case. The emergence of AI gateways is precisely to address this change. Whether enterprises use AI products provided by public clouds or multiple private large model instances deployed internally, they must access and manage them through an AI gateway.
AI gateways primarily address security concerns, followed by auditing issues, and finally typical application scenarios. Currently, commercial customers are mainly focused on realizing these key scenarios.

APISIX AI Gateway
Next, we will introduce the basic implementation methods of the APISIX AI gateway. The technical changes involved in this implementation are relatively minor compared to previous builds, such as the Ingress Controller. This is because in APISIX, the API gateway and AI gateway have already been integrated, and everything operates within a unified framework.
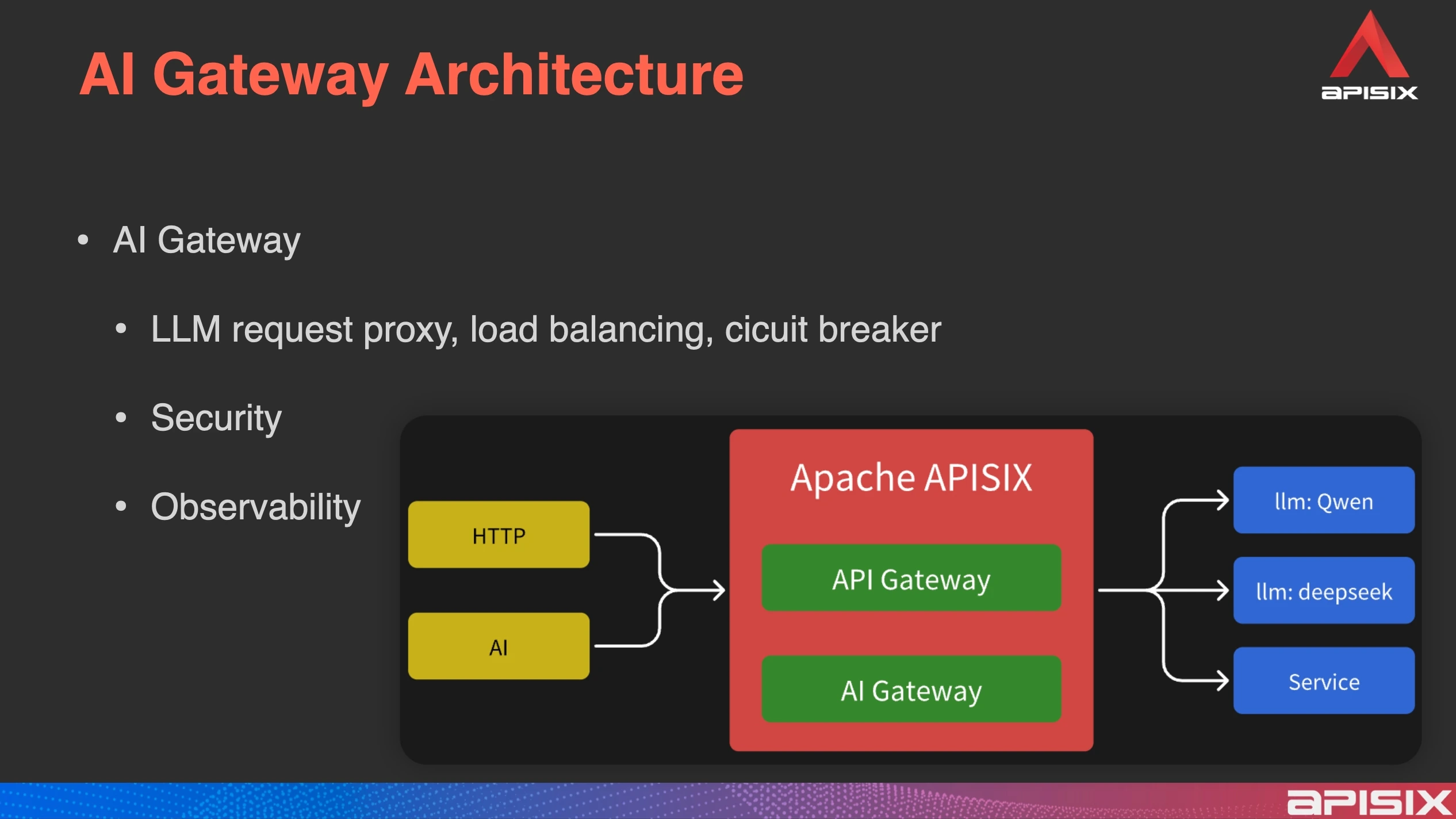
From an architectural perspective, the AI gateway shares essentially the same structure as the API gateway, with only slight adjustments in language extensibility or integration methods. Previously, the plugin system already supported multi-language and replica plugins. Now, the AI gateway is supported in the same plugin framework and still takes the form of plugins. The core design principles remain fundamentally unchanged—only a few critical modifications and upgrades have been made at the underlying level, which have already achieved the desired results.
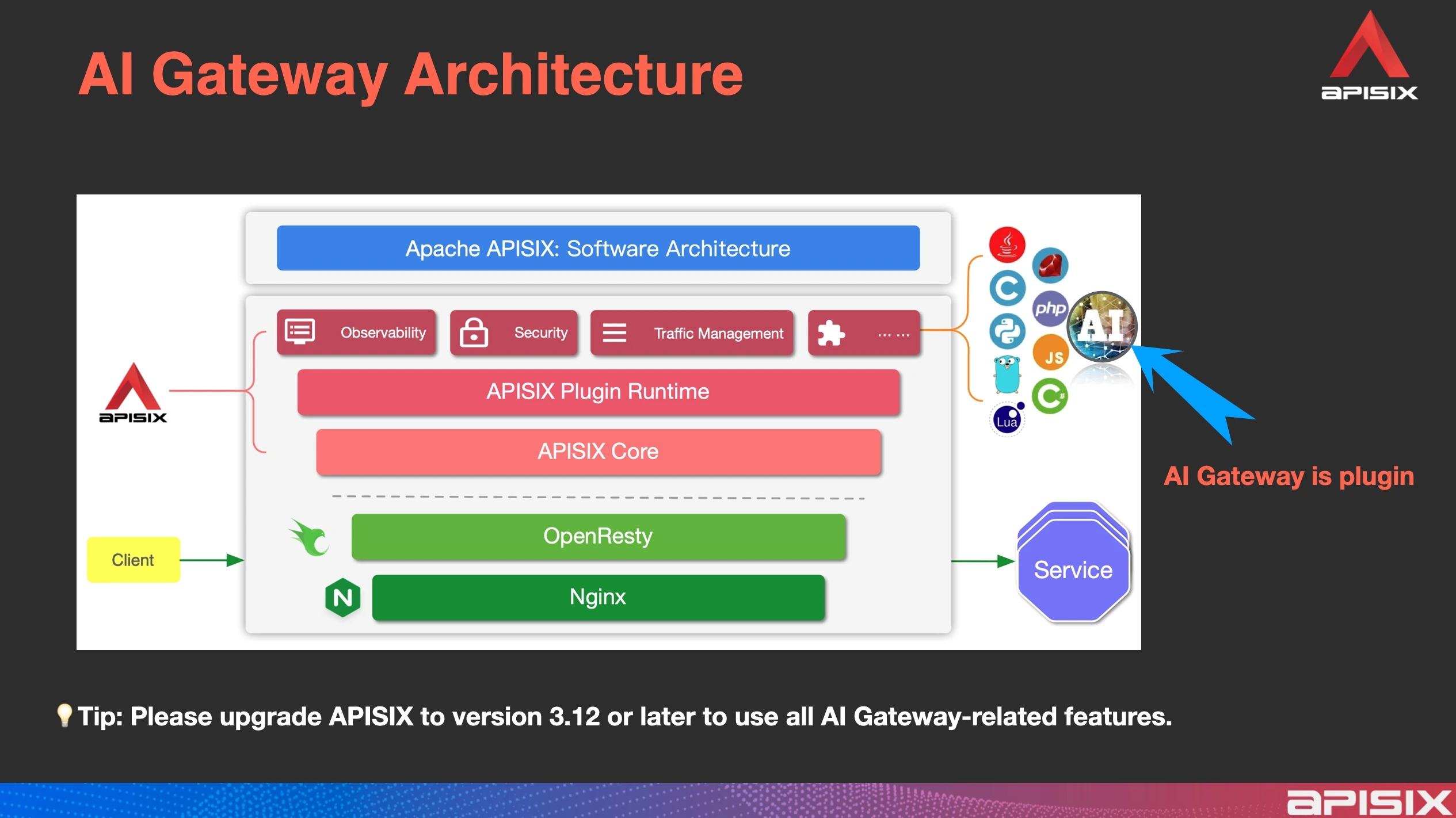
Technical Innovations of APISIX AI Gateway
The main technical challenges or distinctions in implementing the AI gateway within APISIX lie in its differences from traditional HTTP inbound traffic. One primary distinction is the load balancing mechanism for large model instances, which differs from traditional upstream node load balancing. For example, health check methods are different: traditional methods use HTTP GET, while AI gateways require the POST method, changing the invocation approach. Additionally, retry and circuit-breaking strategies also vary.
In terms of observability, the AI gateway focuses on two core metrics: token recording during request and response processes, and latency-related indicators, particularly first-response latency and the number of concurrent connections waiting for the first response. Another factor is cost control. In fact, costs can be quantified in most scenarios by the number of tokens in requests and responses. Security is also a key challenge, which is consistent in the open-source or commercial versions of APISIX.
Currently, we have supported DeepSeek, OpenAI, Qwen, and OpenAI-Compatible in both open-source and commercial versions. The reason for supporting the compatible mode is that there are far more enterprises providing large model services than the aforementioned DeepSeek. Some companies provide private large model services exclusively for commercial enterprises. Although these service providers are not among the three mentioned above, their external interfaces adhere to OpenAI's specifications, thus falling under the "OpenAI Compatible" category.

APISIX AI Gateway Plugin Overview
The APISIX AI gateway has the following commonly used plugins. In terms of proxy, we have not adopted the standard upstream mechanism but instead implemented dynamic proxy through the ai-proxy plugin.

ai-proxy-multi refers to load balancing across multiple large models. ai-proxy and ai-proxy-multi are plugins specifically designed for proxy functions. In addition to proxy capabilities, it is also necessary to implement token-level traffic throttling and health checks for certain upstream services, such as determining whether their tokens are exhausted, which is a common practice.
For a company looking to centrally manage and record AI requests within the organization, it typically only needs to focus on the following four types of services:
AI request proxy;
Token-level traffic throttling and speed limiting;
Content compliance review, especially regarding data leakage issues;
Security review and recording of requests.
Regarding content compliance review, as long as traffic travels over the public network, the requirement extends beyond the enterprise level to national-level regulation. APISIX is initially adapted to AWS-related services to support overseas demands, and other aspects can be researched independently as needed. For instance, in the context of prompt protection: some malicious information may consist of individual "clean" words, but when combined, they can form offensive content. Such issues are difficult to identify through simple means in natural language, thus requiring more efficient mechanisms to explicitly allow or block textual content.
Currently, 90% of the core features have been completed, with the remaining part being personalized add-ons. Like APISIX, the APISIX AI Gateway remains 100% open-source and ready-to-use out of the box. The following figure illustrates the application scenario of the AI gateway proxy for large model invocation.

Example in Intelligent Manufacturing Enterprise
Take a leading enterprise in the intelligent manufacturing industry as an example. Its usage scenarios mainly include two aspects: one is for internal use or its B-end customers, and the other is for some C-end users. The large models accessed by the enterprise involve Qwen, DeepSeek, and various large language model services, including open-source GPT-like models and products from cloud service providers such as Alibaba. The deployment methods also encompass a hybrid of private deployment and online cloud services. Furthermore, the use of models is not limited to text-to-text generation but also includes multimodal scenarios such as text-to-speech and text-to-video, involving a more diverse range of suppliers.

For the enterprise, establishing a unified entry point for requests is particularly crucial. From the client's perspective, the goal is to abstract away the underlying implementation details, so they are not explicitly aware of which service provider's model is being invoked. For example, users only need to ask a question, and the system will automatically route it to the most suitable model. Once users receive a satisfactory response, they typically prefer to continue using the same model rather than switching to a different one.
Therefore, it is necessary to mask the number of internal deployments while reasonably balancing system pressure and achieving internal and external isolation. This is one of the most basic and common capabilities. When internal failures occur, such as large models being unable to continue providing services due to exhausted machine resources, unhealthy nodes should be promptly taken offline.
In terms of compliance, the To B scenario usually poses no significant issues. However, for company-internal To C traffic, there are stringent regulatory requirements at the national level, making security audits particularly important. In the context of large model invocation, i.e., AI request scenarios, the primary requirement in actual use is to record the content of every request and response, which has become a rigid demand. Secondary requirements include token-level quota and speed limiting, automatic forwarding, transparent proxying, and ROI cost-related metrics.
Finally, regarding observability metrics, such as determining which large model responds faster and more stably, the gateway can more effectively direct traffic to the better-performing model services. However, there are many factors to consider, and the model with the fastest response is not necessarily prioritized for more traffic allocation.
In large model services, pricing is a key factor. Different model services have significant pricing differences. Therefore, the various optimization metrics mentioned earlier require more robust observability capabilities to support them. Traditional proxy services may only focus on whether a request is successful, such as judging the result based on HTTP status codes like 200, 300, or 500. However, in the context of large models, it is necessary to introduce more granular token-related metrics to truly achieve effective optimization and cost control.
Future Plans for AI Gateway and MCP Server
Regarding MCP Server, all the aforementioned features have already been covered in APISIX-MCP. Although MCP has not yet officially become an industry standard, it has been widely recognized and actively followed by numerous enterprises. From the trend, MCP is very likely to become a standardized bridge connecting AI models and traditional APIs in the future.
The Application Scenarios and Value of MCP in APISIX
APISIX-MCP can only operate in local environments and lacks unified interfaces for enterprise-level scenarios. However, enterprise users' demands for AI are not "individual-level invocations" but "service-level integration." They hope to achieve cross-system linkage through wearable devices, smart terminals, or other system interfaces, such as "placing a coffee order by voice." This is clearly impossible to achieve through individual local deployments. Therefore, the unified exposure of enterprise-level API interfaces becomes particularly critical.
APISIX can help users more conveniently access AI chatbot services built on standard input/output. It standardizes and encapsulates MCP's communication capabilities, exposing them through the gateway as unified interfaces. This enables AI services that were originally only usable locally to be shared and uniformly invoked at the company level. This not only addresses service exposure issues but also lays the foundation for further governance capabilities such as security policies, access control, and content review.
The Current Stage and Future Development of APISIX-MCP
Currently, MCP has completed the initial stage within the APISIX community, achieving standard input/output service integration. To truly build a service proxy gateway system based on the MCP protocol, ongoing investment from the community and enterprises is still required.
Moreover, MCP differs significantly from traditional HTTP APIs. Although it still falls within the realm of request-response communication, its interaction model is closer to AI model invocation, featuring prompt injection and context passing capabilities. Therefore, it is distinct from generic HTTP interfaces and existing conversational AI APIs, representing a new generation of communication protocols better suited to AI applications.
At present, we are conducting in-depth research on MCP and plan to promote its implementation within enterprises in the near future. From a technical perspective, MCP holds significant potential as a standardized bridge between traditional applications and AI models. Our goal is to encapsulate existing HTTP APIs through APISIX into MCP interfaces, enabling flexible invocation within AI-driven systems. By configuring APISIX with necessary settings, such as importing OpenAPI description files, existing HTTP interfaces can be incorporated into gateway management.
How to transform existing HTTP interfaces into interfaces compliant with the MCP model currently relies on developer intervention, such as writing TypeScript or Python scripts. However, the method I mentioned earlier requires no additional development work. Instead, it can be achieved through appropriate configuration. Once configured, traditional APIs can be exposed in the MCP format and connected with our existing large model services to achieve synergy. This approach allows for the more efficient integration of existing HTTP APIs into our AI ecosystem.
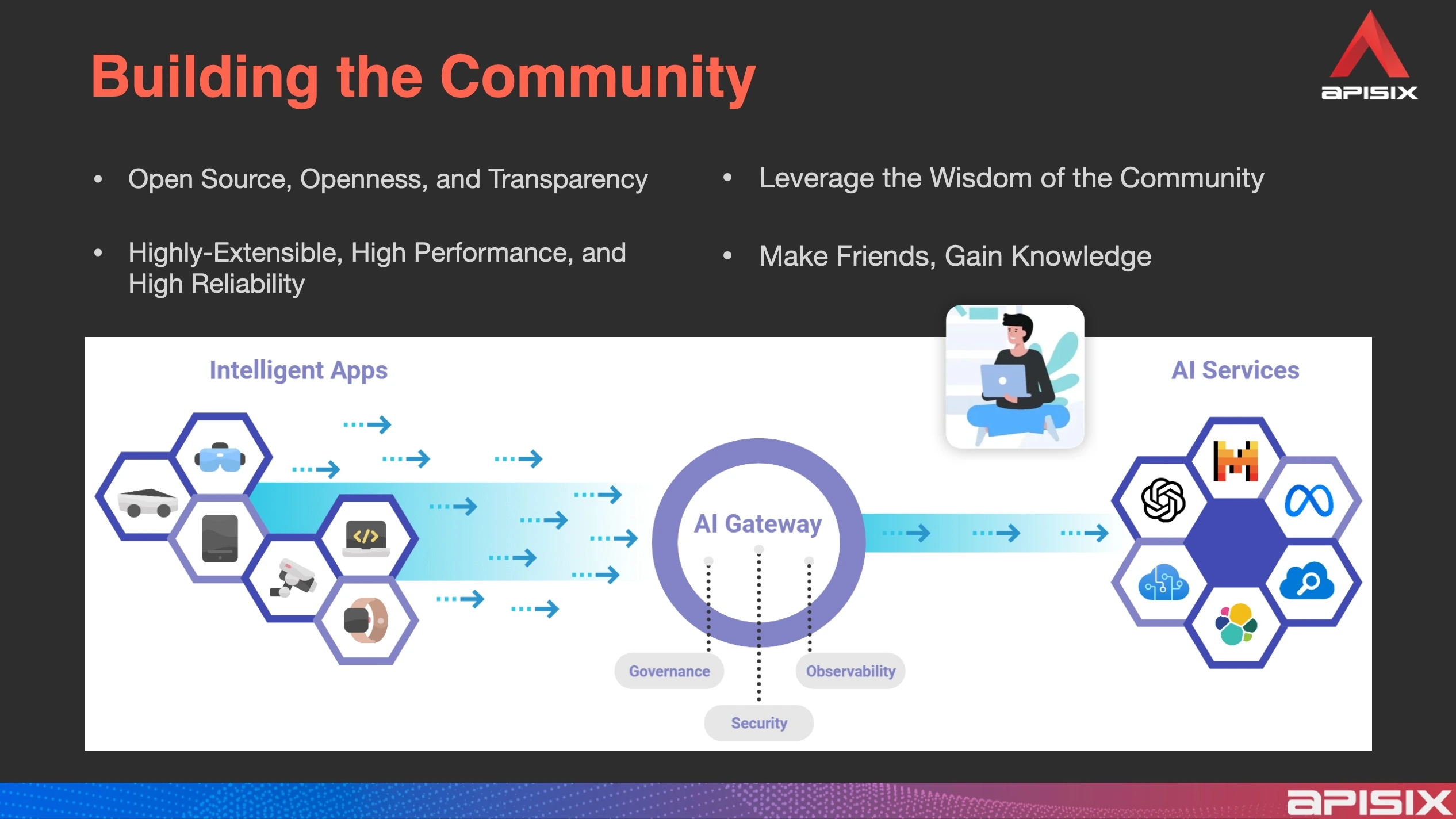
At the same time, issues related to governance, observability, and security must also be taken into account to achieve a unified management and control mechanism. For enterprises, the challenge is not merely about exposing interfaces externally, but more importantly about ensuring unified management, secure control, and compliance requirements.
The core capabilities of MCP have already been made available. We welcome everyone to try them out and share feedback on any potential shortcomings. This feature is still undergoing continuous iteration and will be open to the community once it reaches a certain level of stability and quality.