Benchmark
Benchmark Environments#
n1-highcpu-8 (8 vCPUs, 7.2 GB memory) on Google Cloud
But we only used 4 cores to run APISIX, and left 4 cores for system and wrk, which is the HTTP benchmarking tool.
Benchmark Test for reverse proxy#
Only used APISIX as the reverse proxy server, with no logging, limit rate, or other plugins enabled, and the response size was 1KB.
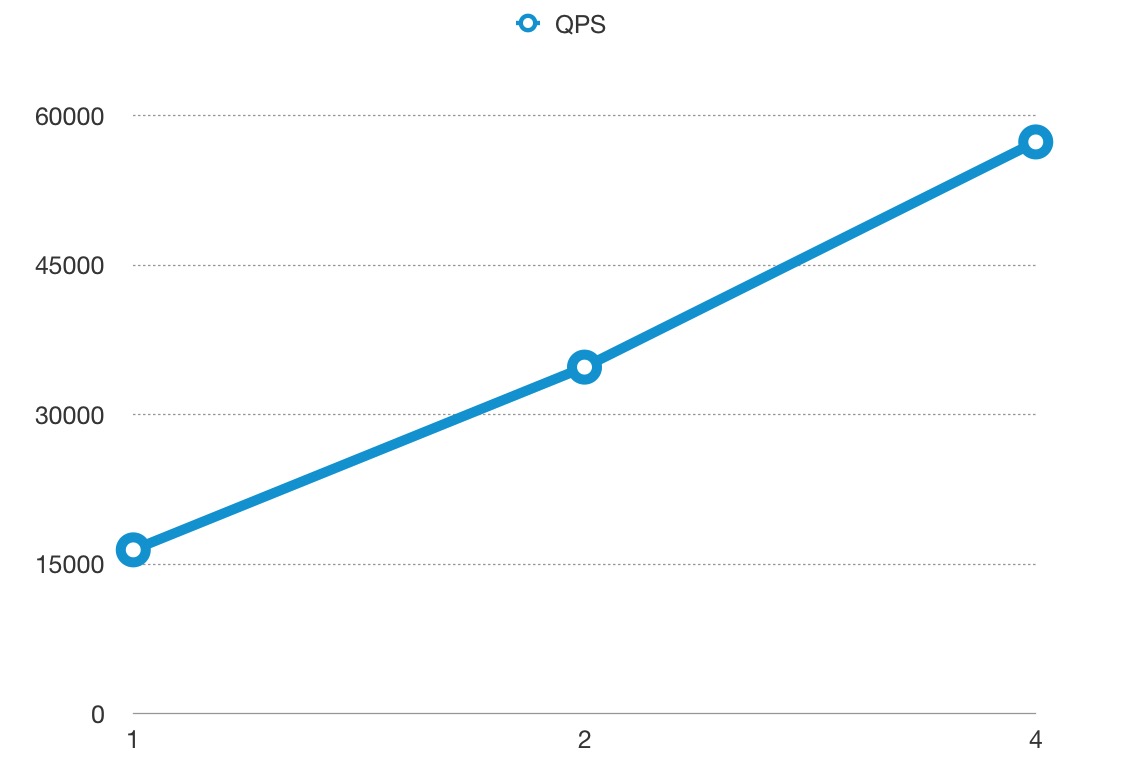
QPS#
The x-axis means the size of CPU core, and the y-axis is QPS.
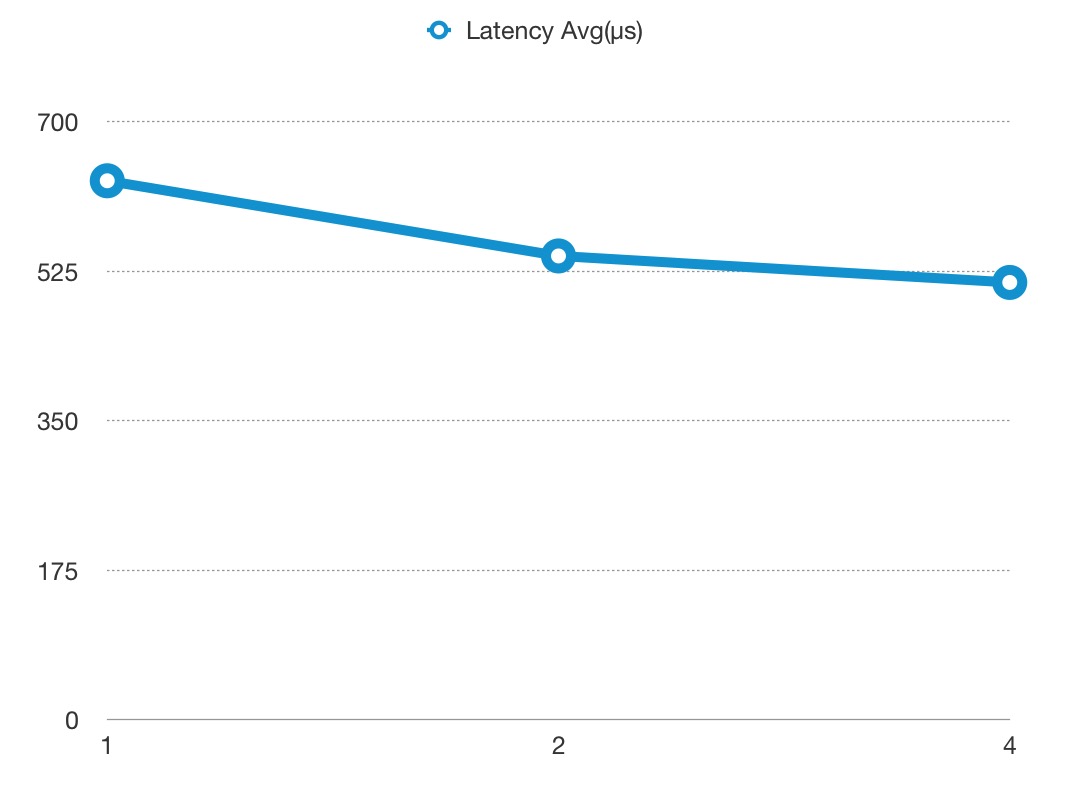
Latency#
Note the y-axis latency in microsecond(μs) not millisecond.
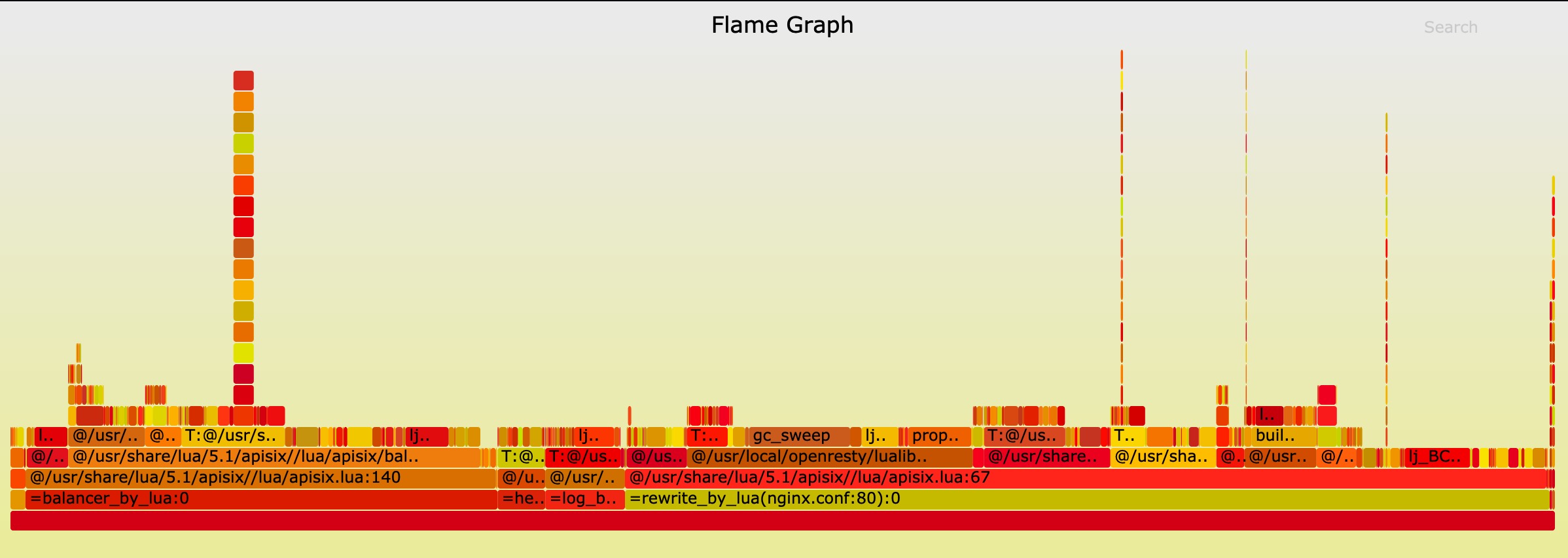
Flame Graph#
The result of Flame Graph:
And if you want to run the benchmark test in your machine, you should run another Nginx to listen 80 port.
note
You can fetch the admin_key from config.yaml and save to an environment variable with the following command:
admin_key=$(yq '.deployment.admin.admin_key[0].key' conf/config.yaml | sed 's/"//g')
curl http://127.0.0.1:9180/apisix/admin/routes/1 -H "X-API-KEY: $admin_key" -X PUT -d '
{
"methods": ["GET"],
"uri": "/hello",
"upstream": {
"type": "roundrobin",
"nodes": {
"127.0.0.1:80": 1,
"127.0.0.2:80": 1
}
}
}'
then run wrk:
wrk -d 60 --latency http://127.0.0.1:9080/hello
Benchmark Test for reverse proxy, enabled 2 plugins#
Only used APISIX as the reverse proxy server, enabled the limit rate and prometheus plugins, and the response size was 1KB.
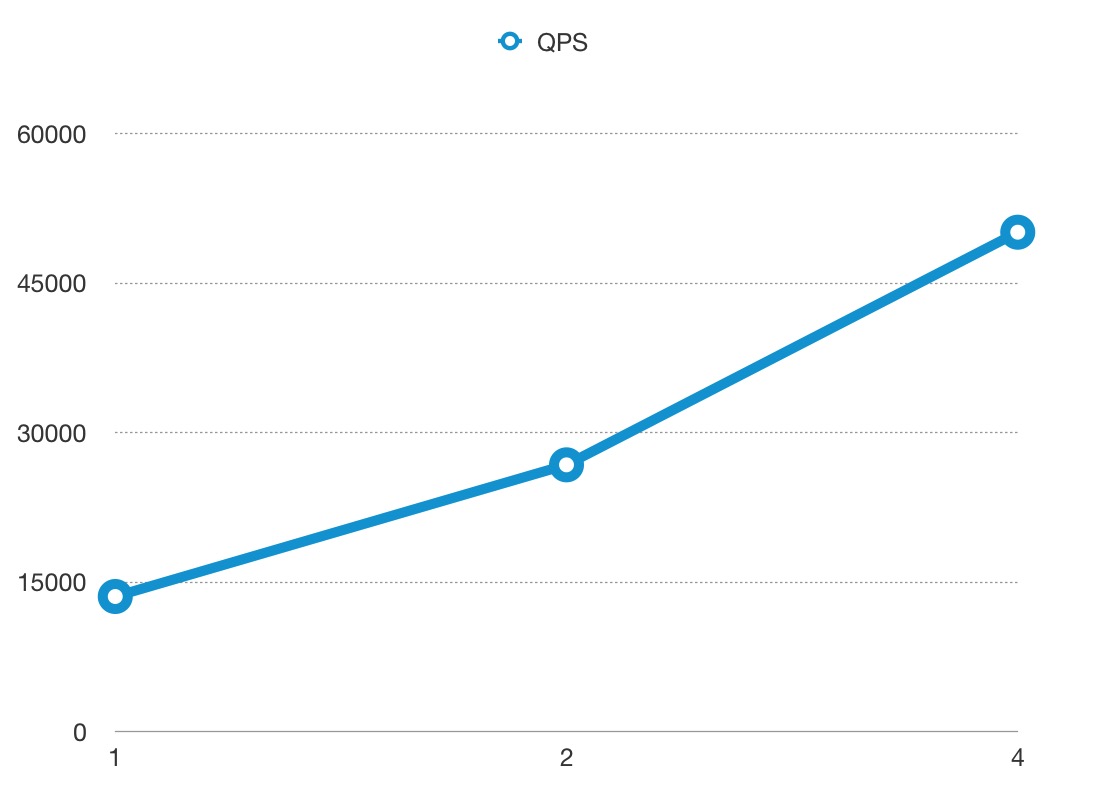
QPS#
The x-axis means the size of CPU core, and the y-axis is QPS.
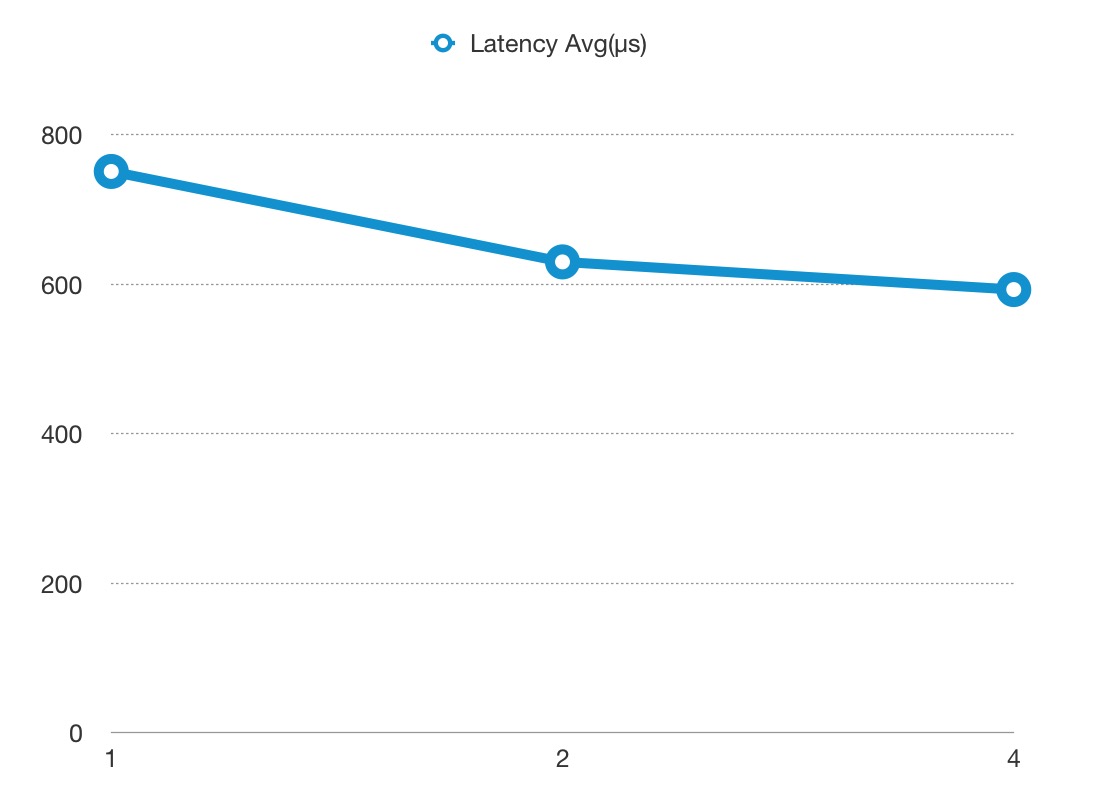
Latency#
Note the y-axis latency in microsecond(μs) not millisecond.
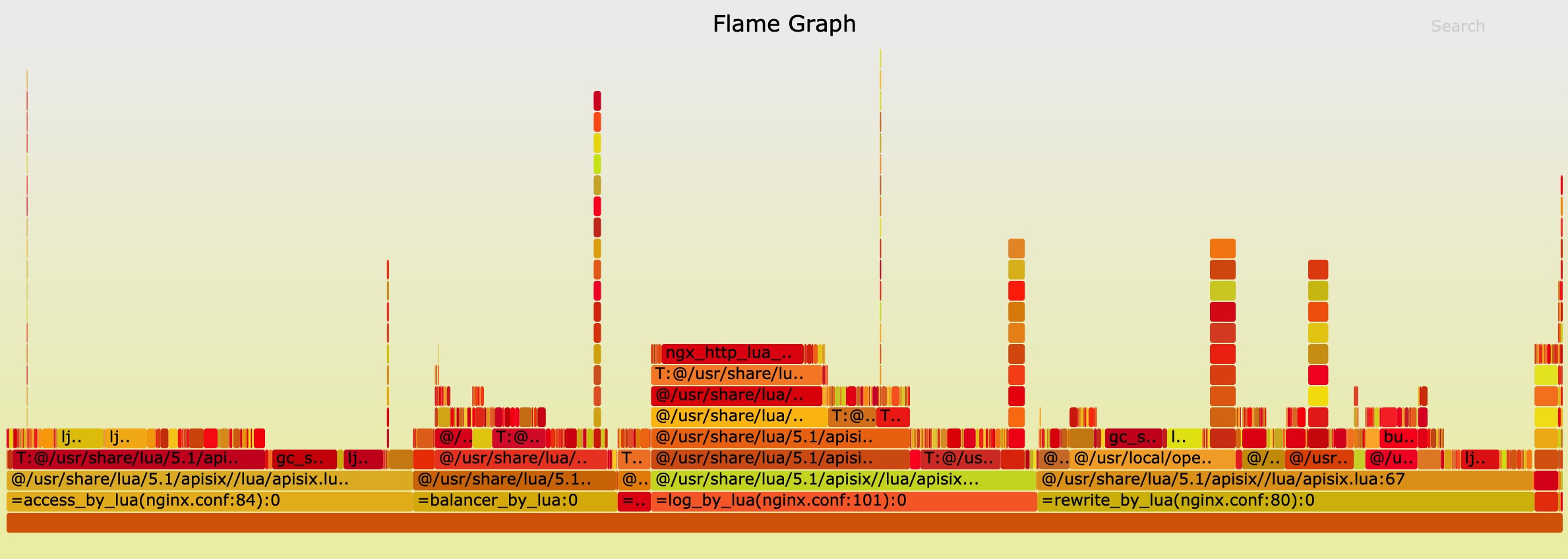
Flame Graph#
The result of Flame Graph:
And if you want to run the benchmark test in your machine, you should run another Nginx to listen 80 port.
curl http://127.0.0.1:9180/apisix/admin/routes/1 -H "X-API-KEY: $admin_key" -X PUT -d '
{
"methods": ["GET"],
"uri": "/hello",
"plugins": {
"limit-count": {
"count": 999999999,
"time_window": 60,
"rejected_code": 503,
"key": "remote_addr"
},
"prometheus":{}
},
"upstream": {
"type": "roundrobin",
"nodes": {
"127.0.0.1:80": 1,
"127.0.0.2:80": 1
}
}
}'
then run wrk:
wrk -d 60 --latency http://127.0.0.1:9080/hello
For more reference on how to run the benchmark test, you can see this PR and this script.
tip
If you want to run the benchmark with a large number of connections, You may have to update the keepalive config by adding the configuration to config.yaml and reload APISIX. Connections exceeding this number will become short connections. You can run the following command to test the benchmark with a large number of connections:
wrk -t200 -c5000 -d30s http://127.0.0.1:9080/hello
For more details, you can refer to Module ngx_http_upstream_module.