
视源股份(CVTE)自成立以来,依托在音视频技术、人机交互、应用开发、系统集成等电子产品领域的软硬件技术积累,建立了教育数字化工具及服务提供商希沃(seewo)、智慧协同平台 MAXHUB 等多个业内知名品牌。其中希沃从 2012 年到 2021 年连续 10 年蝉联中国交互智能平板行业市占率桂冠,已成为名副其实的行业标杆企业。
分享嘉宾简海清,视源股份运维负责人。
为了应对日趋成熟及快速增长的业务现状,希沃又是如何在网关层面进行跟进的呢?
随着技术的飞速发展,在人际交互智能领域,业务需求也对架构迭代有了更高的要求。为了应对日趋成熟及快速增长的业务现状,希沃又是如何在网关层面进行跟进的呢?
网关往期迭代与痛点
希沃网关的发展经历了四个版本的迭代。2013 年公司开始尝试互联网业务,那时候采用了 OpenResty + NGINX 静态配置的方式搭建了最初的网关,开发人员通过 SCP(Secure Copy)进行发布。与此同时一个比较严重的问题就是,每次上线发布都需要运维人员的协助才能保证平滑上线。
随着业务的发展和人员的扩充,2016 年我们开发了第二代发布系统和相关迭代网关。这次是基于 OpenResty 集成了 upsync 模块,同时配合 Consul 来进行服务发现。第二代的系统解决了上一代开发人员无法独立发布上线的问题,但仍需要运维协助才能进行扩容。
之后公司业务开始了迅猛发展,开始对网关以及产品的弹性扩缩能力有了更高的要求。2018 年我们基于 K8s 开发了第三代系统。考虑到仍有部分应用遗留在宿主机上,所以整个网关架构是在 K8s 上使用 Ingress NGINX 来当作第二层的网关,第一层网关仍是 OpenResty 配合的双层网关架构。这种情况下虽然解决了前代发布扩容等自助问题,但又引入了新的麻烦。
业务的快速扩充致使对于整体稳定性的要求越来越高。采用这种双层网关架构后,一层 NGINX reload 和二层网关的路由变更,都会造成长连接断开。这对于一些长连接使用场景会影响较大,比如软件需要获取老师的授课状态时连接突然断开,状态获取中断从而影响授课。
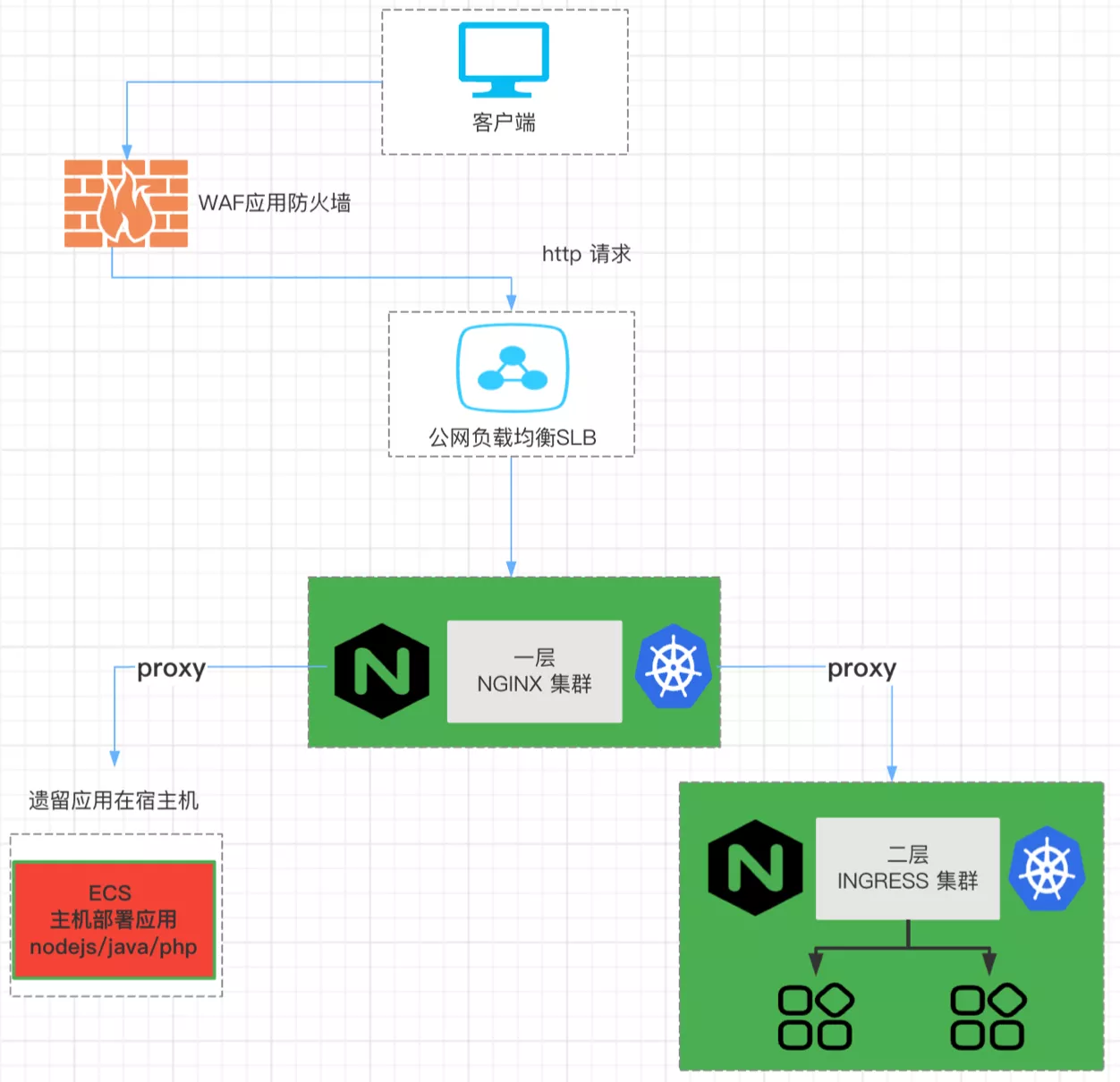
本身双层架构就会带来成本层面的一些增加。同时,从上图的网关流量拓扑图可以看到,除上述遗留问题外也还存在一些架构上的痛点:
- 在双层网关架构下,不管是在第一层网关添加域名、修改配置或者添加一些特殊规则等,都需要 reload NGINX。
- 同时从整体架构来看,组件的配合对于流量控制层面来说比较差。尤其是目前我们的业务用户体量已达到千万级别,一旦客户端出现不可规避的异常,就有可能出现侵蚀服务端的情况,这种时候如果在网关层面没有一定的流量控制能力,对于后端来说将会造成非常严重的雪崩。
因此,基于上述迭代遗留问题和架构痛点,在 2022 年我们引入了 APISIX 来解决上述问题。同时借助 APISIX,也加强了在网关层面对于流量的控制能力。
但是在迁移 APISIX 的过程中,也会存在一些已知挑战。比如:
- ⼀层 NGINX 域名多,定制化规则复杂。目前我们的业务中有 700+ 域名,同时还存在非常多的定制化配置,比如重定向、黑白名单等,这些都需要适配 APISIX 的插件。
- 由于历史遗留问题,⼀层 NGINX 和二层 Ingress 网关还是⼀对多的关系,对于后续的流量切换是不是会很复杂,这也是一个待解决问题。
- 内部存在的双层 DNS 架构。目前 DNS 解析主要用于处理公网和服务器内部的解析,所以对于后续的方案我们更希望是一个能方便回滚同时可以优化内网调用性能的。
迁移 APISIX 后架构调整
面对上述已知的挑战,在迁移过程中主要进行了以下三个角度的操作。由于整个迁移过程没有涉及到研发内容,所以全部都是由运维人员实施的。
在迁移过程中,首先要做的就是 APISIX 路由的生成。基于原本的架构,我们去掉了一层特殊功能,比如 rewrite、set-header 等。弱化一层网关的转发,把所有功能都集中在二层的 Ingress 上,然后基于 Ingress 去生成 APISIX 的路由。同时在 NGINX 配置的基础上适配 APISIX 的插件。
路由生成后,就需要去校验整个转发过程是否正确。我们基于 goreplay 的录制回放来验证路由转发的正确性,同时通过自动化脚本来验证插件功能是否正常。在功能校验通过的情况下,我们会继续验证 APISIX 在性能层面是否满足内部需求。因此,在性能压测过程中我们自研了 elastic-apm 插件,同时针对部分影响 QPS 的插件进行了性能优化。
处理完功能跟性能相关的问题后,最大的挑战就是流量切换了,因为流量切换将直接关乎生产质量。
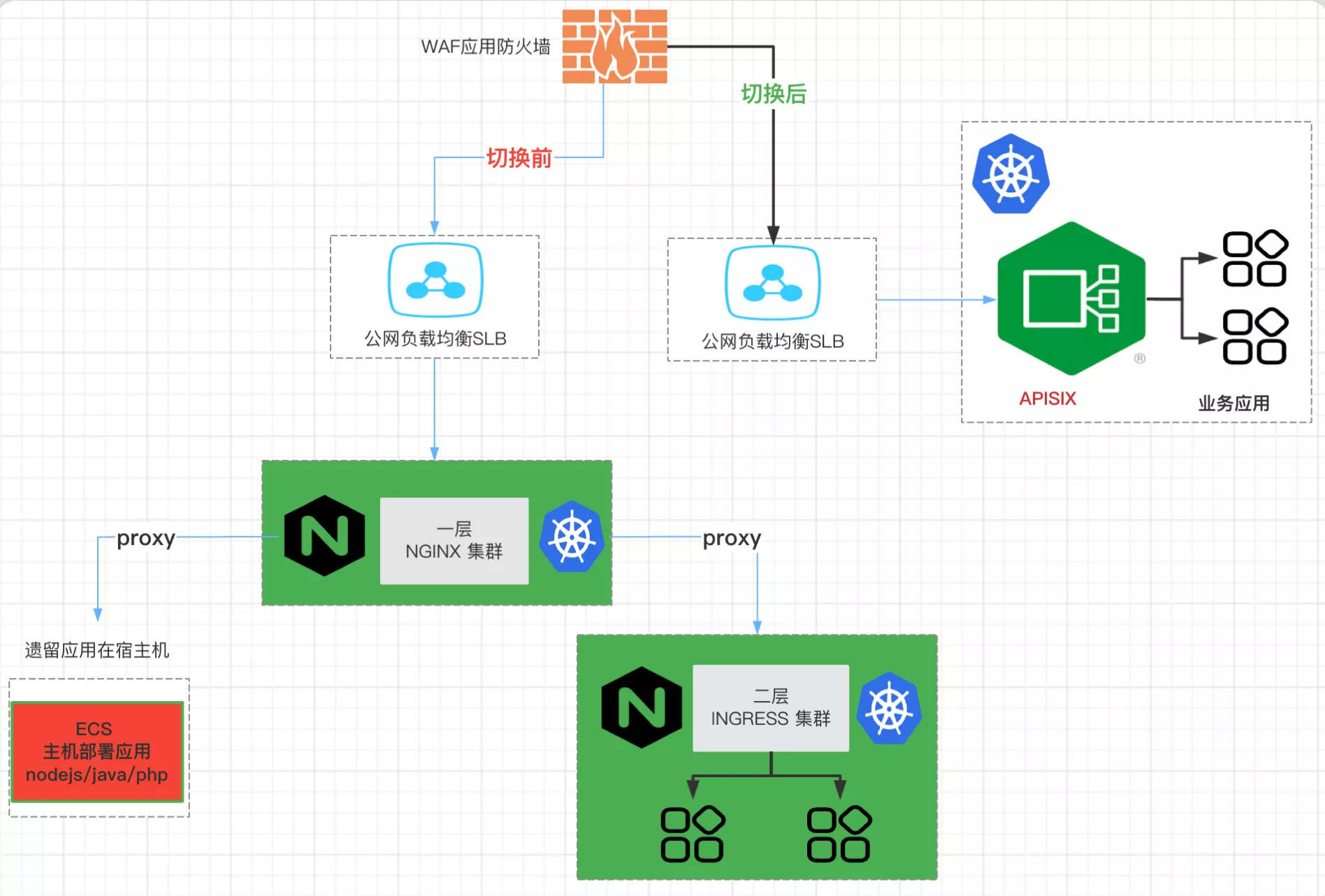
虽然前边我们已经使用了 goreplay 进行流量录制回放,但我们仍然需要一个比较可靠的回滚方案。假设流量切换造成了异常,比如转发异常或者是 APISIX 出现崩溃时,能够进行快速回滚操作。基于此,我们首先切换了公网流量,因为公网是通过 WAF 回源到 SLB 来进行流量切换的,这时如果我们切换到 APISIX,就可以很方便地去修改回源地址来将整个流量进行回滚,如上图标注「切换」字样所示。这个异常情况下的流量切换过程基本是在秒级别,可能 10 秒内就把所有流量都切回来了。
完成了公网流量切换的情况下,顺利运行了几天,我们就通过 APISIX 将内网流量也进行了变更,然后整个生产上的切换就全部完成了。但是这个上线过程中,其实我们还是遇到了一些问题的。
迁移过程中的问题与解决方案
Prometheus 插件转发延迟
这个是在我们内网测试环境中发现的一个问题。由于我们的内网是 all-in-one 的测试环境,所有部门都使用同一个 APISIX 的入口,所以路由规则非常多,达到 4000+。这样就会导致每次拉取 Prometheus 插件时, metrics ⼤小达到 80M+,造成单个 worker 进程跑满,从而造成 worker 的转发延迟。


这个问题是目前 APISIX 开源版本存在的一个现象,主要是因为业务流量和内部 API 流量(比如Prometheus metrics 和 Admin API)都共用 worker 造成的。我们在之前是针对 Prometheus 插件进行了修改,其中延迟相关的 metrics 占用了 90%以上(如上图所示),所以我们将这部分采集去掉了。去掉这部分后,业务层面还是满足了我们的监控使用需求,并未造成影响。
不过最近我们针对这个问题又有了新的方案,目前还处于 demo 阶段。这套新方案是对 NGINX 源码进行修改,通过多启动⼀个或多个 worker 进程(isolation process) 来专⻔监听特定端口的请求(比如 Prometheus、Admin API、Control API 等),不监听处理正常业务端口请求。其它的 worker 进程则取消监听上述端口,只处理正常业务端口请求,来确保 APISIX 内部请求和正常业务请求间不会互相影响。


默认路由匹配异常
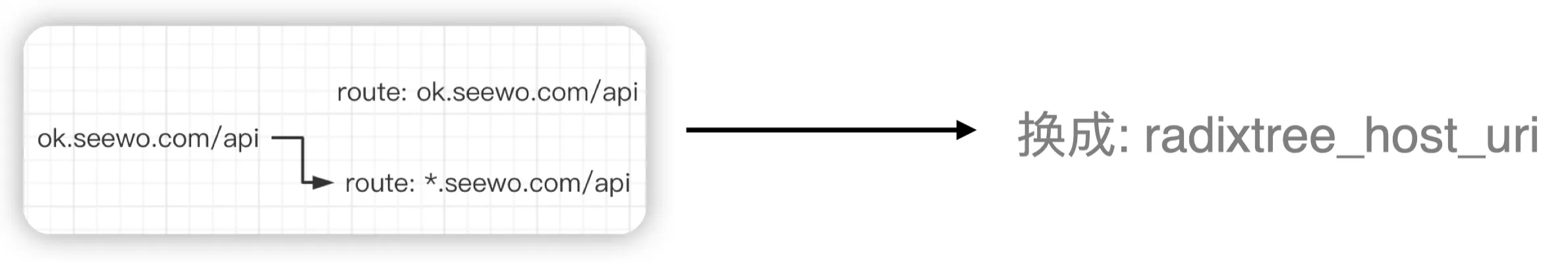

在上线 APISIX 后,我们发现域名并没有走精确匹配模式,而是采用了通配符匹配,这跟 NGINX 的域名最长匹配是不一致的。为此,我们通过更换路由策略,将 URL 方式改成了 host+URL 的方式,解决了该问题。
但关于 APISIX 基于 URL 路由策略作为默认路由的问题,大家可以在自己的生产环境中进行压测后再决定是否保留。
假如你的生产场景中属于 URL 特别多、域名特别少的类型,那 APISIX 这种默认路由策略是完全 OK 的。但在我们的业务场景下,并没有这么多 URL,所以采用 host+URL 的方式是更满足我们的性能需求。
默认自动绑核问题
在云原生的背景下,大部分用户都会选择将 APISIX 部署在容器中使用。但 APISIX 在默认配置下会进行自动绑核,这样就会导致在容器化场景下,可能只会用到前几个核心,造成前几个核心跑满而后几个核心仍处于空闲的状态。虽然 CPU 使用率不高,但是会使 APISIX 转发出现延迟。

不过 APISIX 社区最近已经开始调整这个配置,将 worker_cpu_affinity 配置的默认值从 true 改为了 false。因此这个问题目前在 APISIX 版本中已经解决了。
版本升级兼容问题
在上线 APISIX 的过程中,我们还发现在较老的系统或 OpenSSL 库中,它的 ssl_ciphers 和服务端默认值无交集,从而造成 SSL 握手失败。
针对这个问题,我们建议大家在上线 APISIX 之前,先通过一些 SSL 工具先去探测一下当前旧网关与 APISIX 网关的 SSL 握手交集是否正确或满足使用场景,然后再进行规模化的迁移调整。
除此之外,在 APISIX 发布 2.15 LTS 版本后,我们就在内网进行了升级,但是升级后就发现了一些路由匹配相关的问题。
因为从旧版本升级到新版本时,存在一些兼容性问题,导致 redirect 插件参数 http_to_https 为true 时,参数 http_to_https 和 append_query_string 校验失败,进而路由加载失败,导致路由丢失。这种情况下就会在路由匹配时出现 404 或者转发到其他上游的情况。
目前这个问题已经在 APISIX 的 master 分支中解决了,但是并没有针对 2.15 版本进行单独解决,所以大家在使用该版本时也需要留意这部分问题。
应用 APISIX 的收益及展望
虽然前边提到了一些我们在上线 APISIX 过程中遇到的问题,但是在应用 APISIX 之后,给公司业务层面还是带来了很多价值的。比如:
运维效率提升。 使用 APISIX 后,再也不存在 reload 相关的烦恼,可以做到随时更新路由和证书等,给开发人员带来了操作上的便利。
流量控制能力提升。 使用 APISIX 后,我们在熔断和限流方面都得到了提升,从而加强了在流量管控层面的能力,进一步稳固了整个业务核心流程。
自研插件,增强网关能力。 得益于 APISIX 的强拓展性和自身插件性能的优异,我们也会更主动地去开发一些插件。比如我们在 APISIX 上集成了统一鉴权的能力,新业务无需单独对接鉴权系统,加快了产品迭代流程。
 Click to Preview
Click to Preview去掉了冗余的一层 NGINX,实现降本增效。 之前的双层网关架构中,一层的 NGINX 对于开发人员并不透明。现在将双层网关合并为一层后,开发人员可以很清晰地看到架构中一些关于路由或插件等配置,对于排查问题来说更加方便快捷。 在后续使用 APISIX 的规划中,我们还是会继续在网关层面进行增强。比如开发针对内部业务的自研插件,提供多租户的能力,或者是将 API 管理的功能带到网关层面等等。
当然在这个过程中,我们也在积极回馈社区。目前已在社区中贡献了 8 个 PR,帮忙完善和修复了一些生态插件相关的问题。比如完善 batch_request 支持自定义 uri、为 hmac-auth 插件提供请求 body 校验等功能。
希望在后续的实践过程中,我们可以更全面地使用和发挥 APISIX 的特性,更加积极地探索 APISIX 的使用场景。期待未来有更多的共建功能上线。