
作者:付家浩、许伟川,荣耀 PAAS 平台部工程师。本文整理自 2025 年 4 月 12 日两位工程师在 APISIX 深圳 Meetup 的演讲。
荣耀简介
荣耀成立于 2013 年,是全球领先的智能终端提供商。荣耀的产品已销往全球 100 多个国家和地区,并与 200 多个运营商建立了合作关系。荣耀在全球的体验店与专区专柜超 52000,在网设备数超 2.5 亿。
作为全球领先的 AI 终端生态公司,荣耀致力于变革人机交互方式。凭借涵盖智能手机、个人电脑、平板电脑、可穿戴设备等多元化的创新产品组合,荣耀旨在赋能每一位用户,让每个人都能轻松踏入并享受崭新的智能世界。
荣耀网关平台的演进与架构
演进
荣耀于 2021 年开始接触流量网关产品,Q3 开始对 APISIX 进行相关的预研工作,在 Q4 正式引入 APISIX,启动了荣耀公司内部流量网关平台的建设。
2022 年 APISIX 网关在荣耀内部正式投入商用。Q1 面向 To C 业务的流量接入试点推广;Q2,开放平台 API 供部署平台使用,支持流量调度和容器实例上报。此外,在部署平台尚未完全构建完成的情况下,能够通过脚本调用 API 的方式进行流量接入与调度。
2023 年,Q1 完成了 APISIX-CP 容器化能力的构建,Q3 上线了 APISIX-DP 弹性伸缩能力。Q4 单集群超千万连接,年底完成了全量云服务 ToC 业务覆盖。
2024 年,Q1 完成 APISIX-DP 容器化的构建,Q2 运行面架构优化至 2.0,Q4 达成单集群百万 QPS,年底覆盖荣耀全量业务。
到目前为止,荣耀内部基于 APISIX 的网关平台的流量峰值达数百万 QPS,基于 APISIX 的可扩展能力,目前有近百个自定义插件。
接下来荣耀技术团队将探索 AI 与网关的有效结合。另外,如何实现网关与 Kubernetes 的服务自动上报能力。
网关平台架构
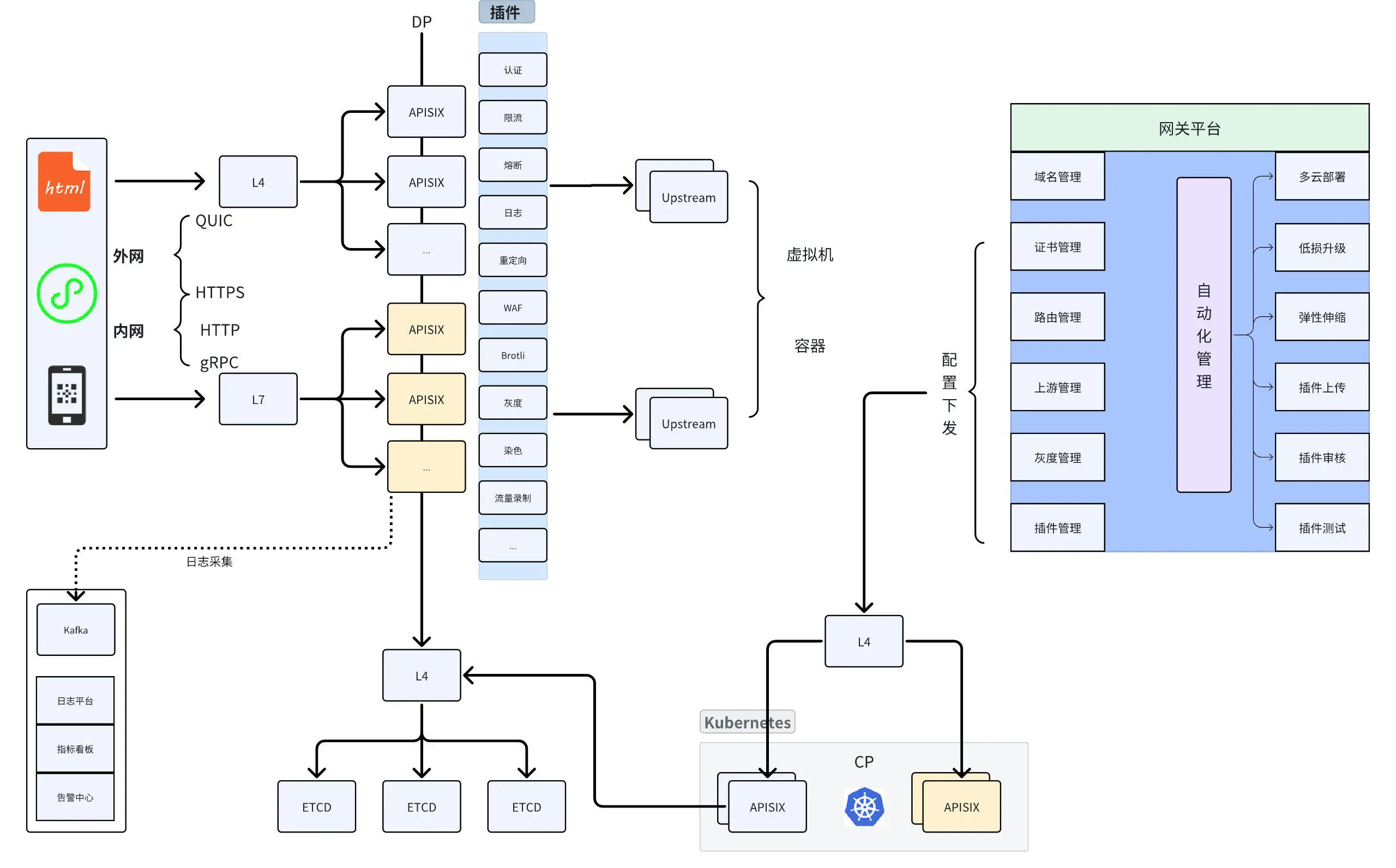
网关架构详解
- 内外网支持的协议
荣耀的网关架构分为内网访问和外网访问两部分:
- 外网支持协议:QUIC 和 HTTPS。
- 内网支持协议:HTTP、HTTPS 和 gRPC,其中 gRPC 主要承载与 AI 相关的流量,近一年内其 QPS 明显上涨。
- 负载均衡器与代理选择
- 在 APISIX 前端部署了一台负载均衡器(LB),用于接入公有云的四层代理和七层代理。
- 四层代理:最初用于发布所有路由,但随着业务上线,发现四层代理无法解决某些问题,因此切换为七层代理。
- API 集群与插件市场
- API 集群:不同集群共享 etcd。
- 插件市场:列出了常见插件,如认证、限流、WAF、染色等。
- 上游部署:主要以容器为主,少量虚拟机。容器对接部署平台,平台在容器部署完成后调用 API 上报流量和实例信息。
日志采集与分析:未使用原生 Prometheus 插件,而是通过 Kafka 采集日志,结合 Elk 进行指标分析和告警能力的建设。
etcd 负载均衡优化:在 etcd 前端增加了一层 LB,解决直接连接 etcd 节点时负载不均的问题(如节点连接数过高)。
网关平台功能
- 用户全流程管理:从域名管理、证书管理到路由注册,覆盖灰度功能。
- 插件管理:用户通过插件市场上传插件,平台进行审核和部署。
- 智能化部署:屏蔽底层云差异,支持自动化部署和公共云适配。
低损升级
由于平时插件变更频繁,因而业务比较关心低损升级。通过 LB 将 APISIX 节点摘除,确保流量完全下线后再进行升级,实现无损和自动化升级。
弹性伸缩
应对大流量场景时,通过虚拟机快速扩容和及时恢复,支持自动扩容(如 CPU 超过阈值时自动扩容机器并挂载到 LB)。
插件部署与自动化
- 插件部署:管理面平台与运行面关联,通过配置下发到 CP 进行容器化部署。
- CP 和 DP 隔离:CP 和 DP 连接 etcd 集群,实现管理面和运行面的隔离。
荣耀海量业务下的网关实践
关于 APISIX 在荣耀海量业务下的实践,最初我们使用 APISIX 的原生插件,随着业务发展和要求,原生插件已经无法满足我们的需求。因此我们基于平台或者用户基于自身的需求扩展了一些插件,目前已经有 100 多个。
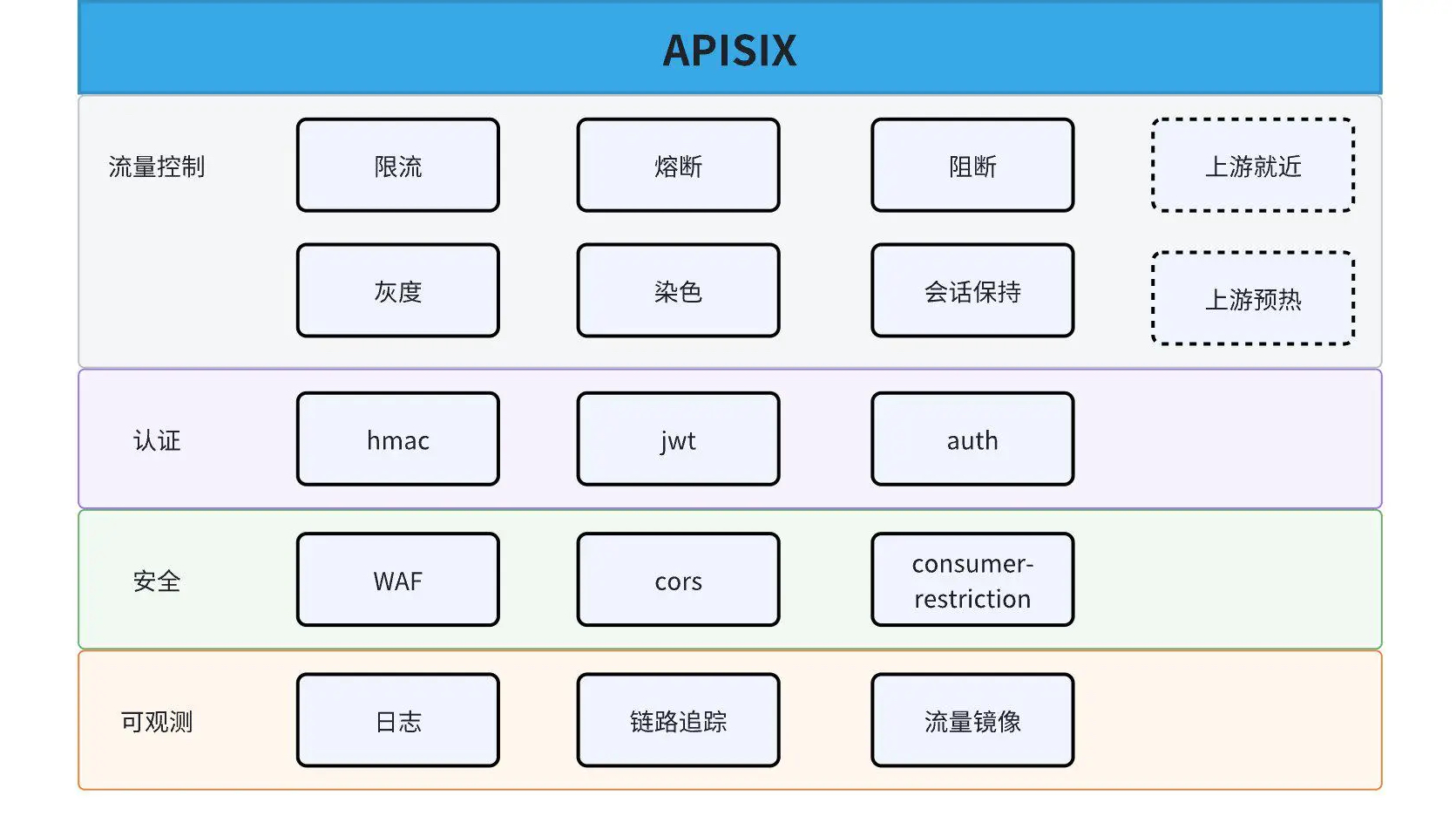
插件分类
插件主要分为四个部分:流量控制、认证、安全、可观测。由于我们的集群基本都是通过双 AZ(Availability Zone,可用区)部署实现可靠性,因而衍生的问题就是跨 AZ 的时延,这个问题需要网关来解决,通过网关实现同 AZ 就近转发。
1. 可观测:流量镜像
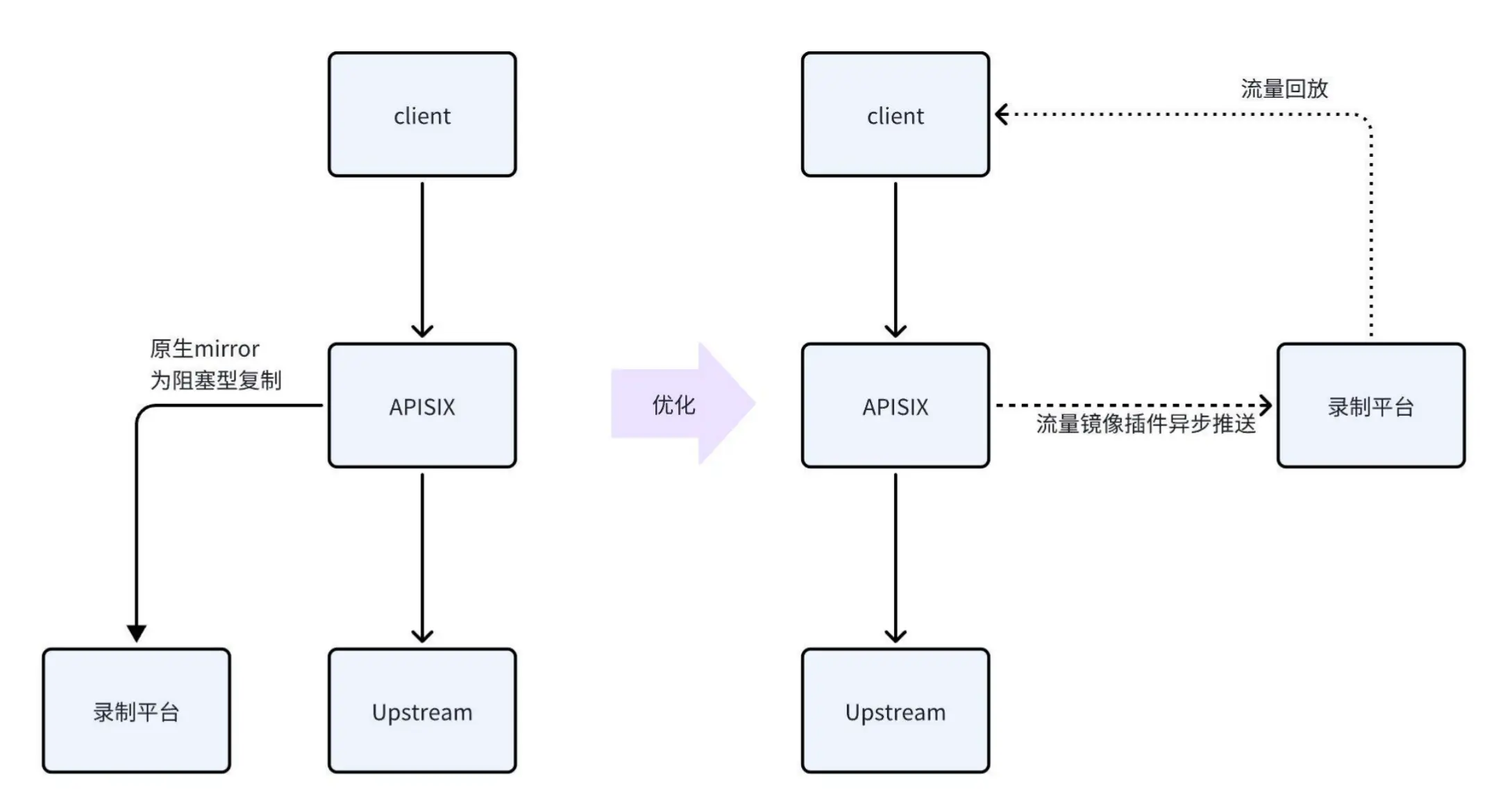
请求处理与流量镜像
当请求到达 APISIX 后,流量会被继续转发至上游。在此过程中,请求会被镜像至第三方物资平台。然而,该镜像过程为阻塞型操作,即当录制平台未返回流量时,客户端请求会被阻塞。若录制平台出现故障,将严重影响正式流量的稳定性。因此,我们未选择使用 NGINX 或 APISIX 内置的镜像能力,而是通过自定义插件实现异步处理。
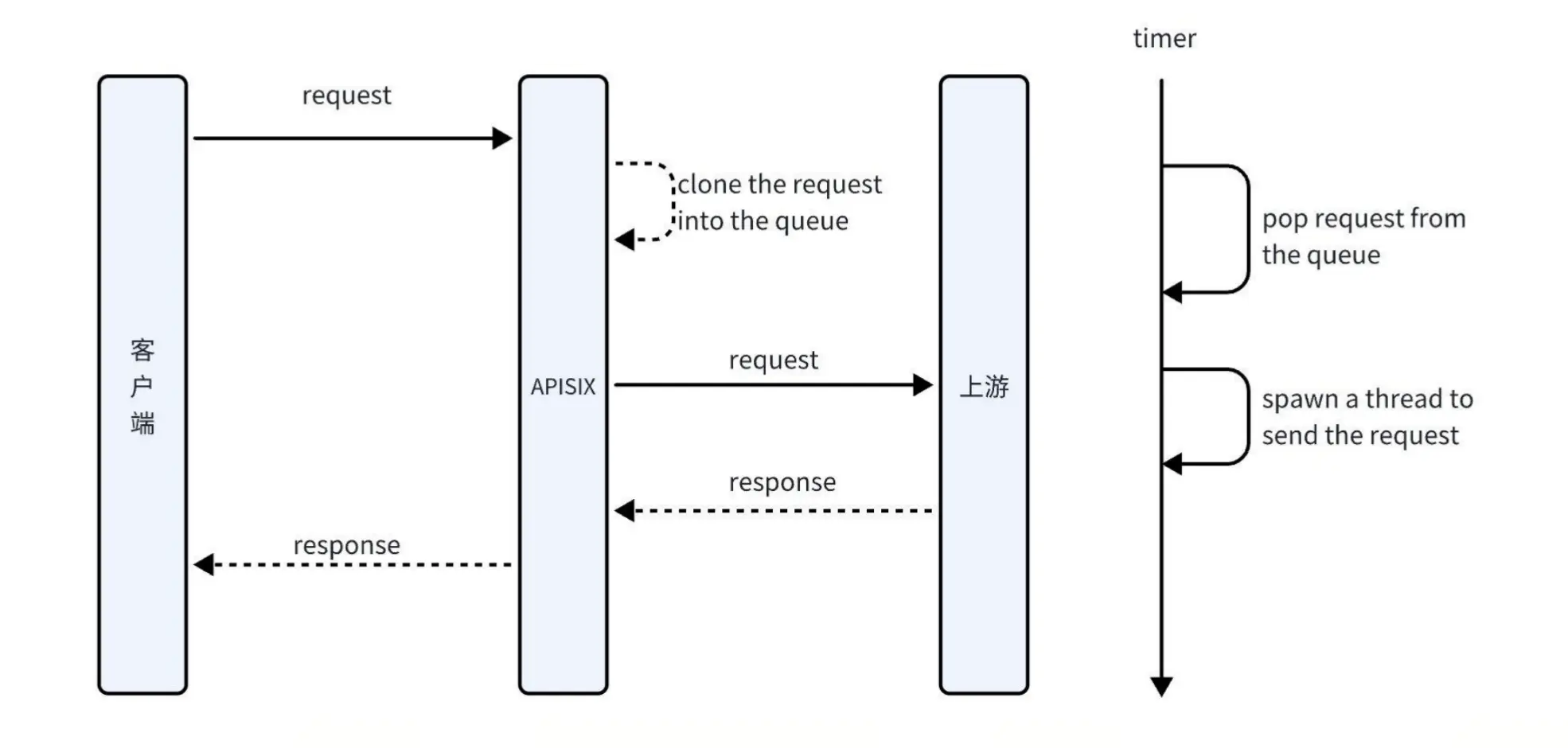
自定义插件实现
自定义插件的实现方式如下:
- 请求到达时:将请求异步保存至队列中。
- 上游处理:APISIX 将请求转发至上游,上游返回响应后,客户端请求流程结束。
- 异步录制:通过异步线程从队列中提取请求,并将其发送至录制平台进行数据录制。由于录制请求包含时间戳,异步操作不会影响正式流量。
录制平台功能
录制平台负责收集数据,支持以下功能:
- 回放时调整流量规模(扩大或缩小)。
- 为回放请求添加特定的请求头,从而实现全链路压测能力。
队列与线程优化
为确保系统性能,我们支持配置队列大小和线程性能参数。虽然异步转发不会直接影响正式请求,但若异步流量过大,仍可能增加 APISIX 的 CPU 负载。因此,建议根据业务需求选择最优参数,以平衡性能与录制效率。
2. 流量调度:灰度插件
当前灰度能力已实现平台化,并对灰度插件进行了优化改造。
灰度插件优化
传统灰度插件支持基于规则或流量百分比的灰度功能,但其流量百分比灰度可能导致流量分配不一致,例如同一请求在不同时间可能被分配到不同的灰度环境。这种情况在 To C 场景中可能影响业务的稳定性。
为解决这一问题,我们在灰度插件前引入了哈希插件 key-hash,结合灰度插件实现稳定的灰度百分比分配。具体实现方式如下:
- 支持基于特定请求头或 Cookie 的输入进行哈希计算。
- 将哈希结果作为灰度插件的输入,用于确定流量分配的百分比。
通过这种方式,确保流量分配的一致性和稳定性,满足 To C 场景的业务需求。
全链路灰度插件改造
在全链路灰度场景中,我们对灰度插件进行了改造,以实现精准的流量调度。如图所示,服务 A 存在灰度状态,而服务 B 和 C 处于正式环境。为实现服务 A 到 B 的流量保持当前流向,同时将服务 C 的流量导向灰度环境,这一目标是通过网关能力实现的。以下是具体实现方式。
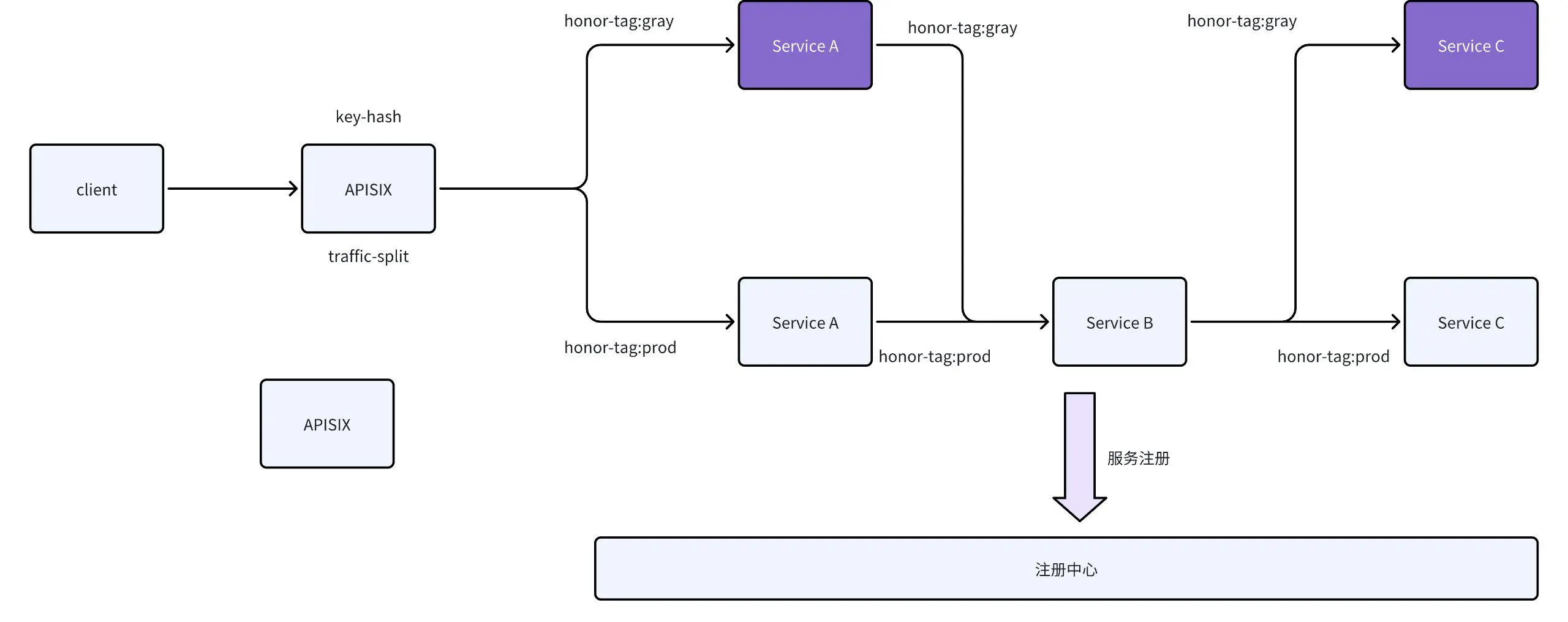
1. 流量打标与请求头插入:
a. 当流量通过 APISIX 网关时,会根据灰度策略对流量进行打标。
b. 若通过的流量为灰度流量,网关会在请求中插入特定的请求头(如 honor-tag:gray),标识该请求为灰度流量。
2. 服务注册与标识:
a. 服务 A 在注册到注册中心时,会将自己的灰度标识(如 gray)一并注册。
b. 注册中心维护了服务的灰度标识与实例的映射关系。
3. 服务间调度逻辑:
a. 服务 A 调用服务 B:
i. 服务 A 收到请求后,首先检查请求中是否包含灰度标识(如 `honor-tag:gray`)。
ii. 若请求包含灰度标识,服务 A 会根据该标识从注册中心获取服务 B 的灰度实例,并优先调度灰度实例。
iii. 若服务 B 没有灰度实例,则降级调度正式实例。
b. 服务 B 调用服务 C:
i. 服务 B 收到服务 A 传递的灰度标识(如 `honor-tag:gray`)后,同样会根据该标识从注册中心获取服务 C 的灰度实例。
ii. 若服务 C 存在灰度实例,则将请求调度到灰度实例;否则,调度正式实例。
4. 全链路灰度实现:
a. 通过请求头的透传(如 honor-tag:gray),确保灰度标识在服务链路中保持一致。
b. 服务链路中的每个节点根据灰度标识进行调度决策,从而实现全链路灰度能力。
通过上述改造,我们实现了全链路灰度的精准调度,确保灰度流量在整个服务链路中的一致性和稳定性。
3. 流控与安全
APISIX 提供了丰富的插件能力,涵盖单机限流和分布式限流方案。以下是针对单机限流方案的优化实践。
3.1 限流
单机限流
问题描述
在最初采用单机限流方案时,我们遇到了一些挑战:用户若需设置全局限流值(如 4000 QPS),需手动协调平台管理员确认网关节点数量,并根据节点数量分配限流值(如 2 个节点需各配置 2000 QPS)。此过程繁琐且易出错。
在弹性伸缩场景下,网关触发扩容或缩容时,限流值可能出现不匹配问题。例如,当 CPU 使用率达到 80% 时触发弹性扩容,假设初始配置为每个节点限流值为 2000,扩容后节点数量增加至 3 个,总限流值会变为 6000,这可能导致后端服务因流量超出承载能力而异常。
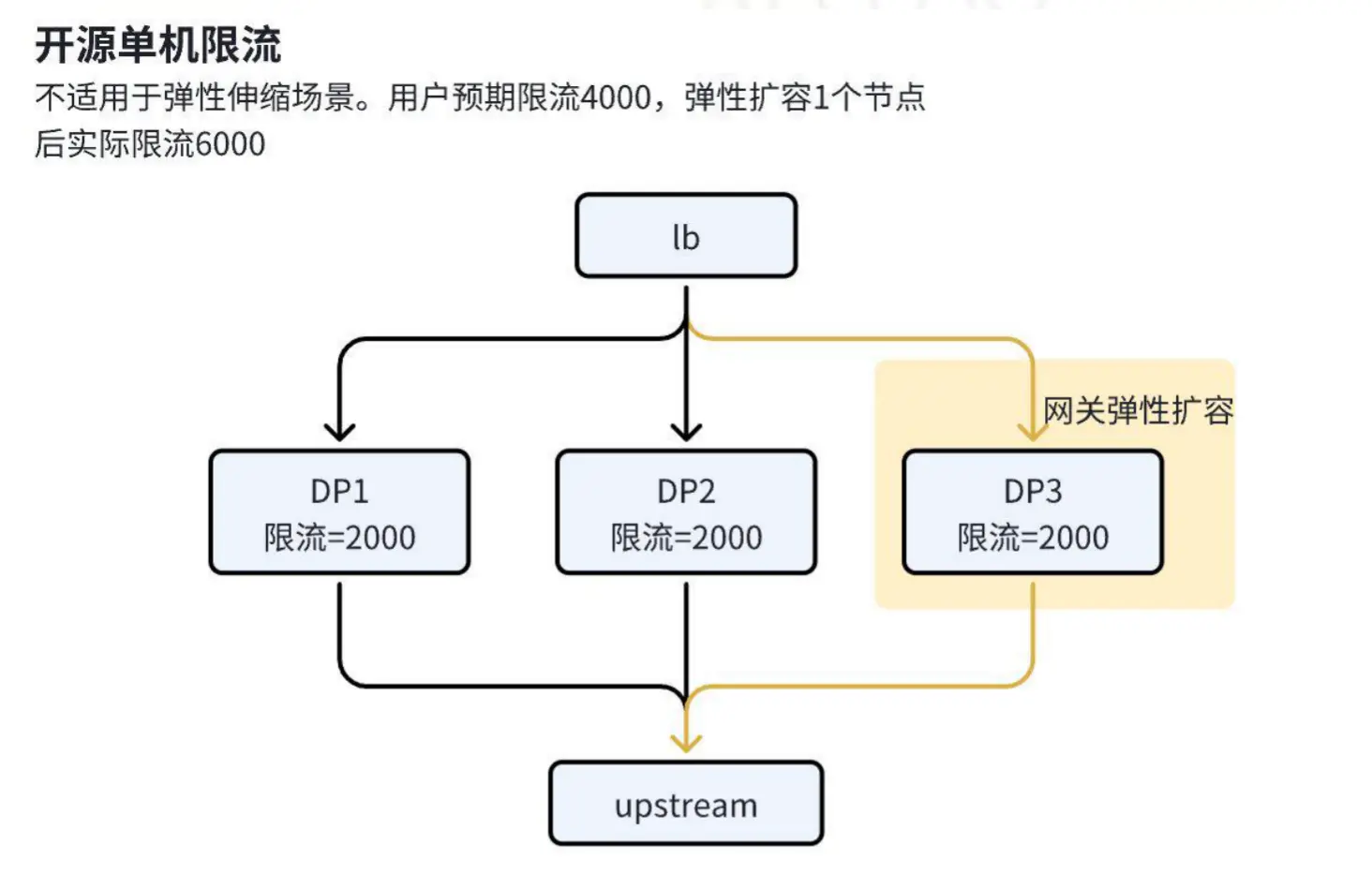
优化方案
为解决上述问题,我们引入了以下优化措施:
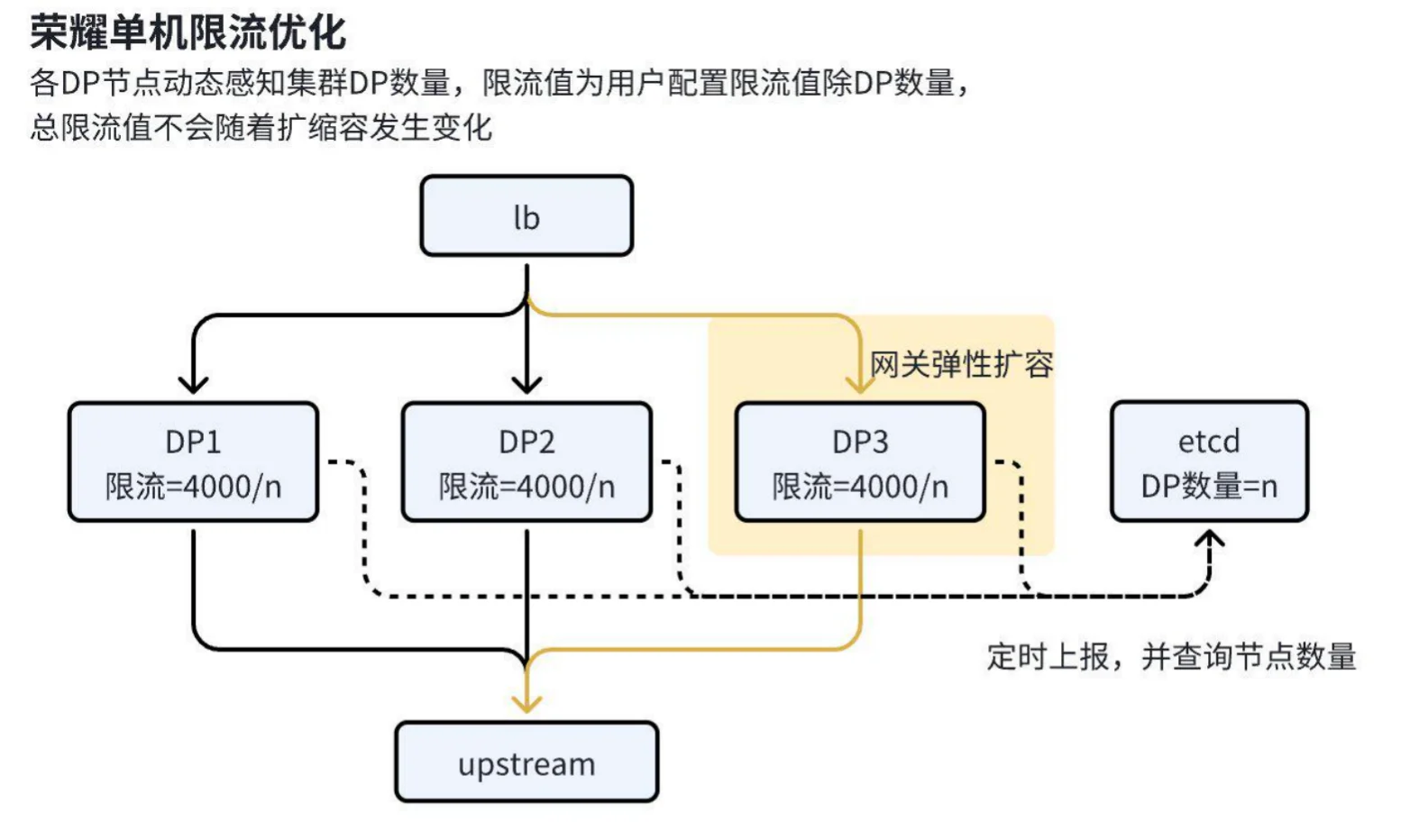
1. 节点信息上报与维护
a. 实现方式:采用开源的 server-info 插件,定时将每个 DP 节点的信息(包括主机名等)以带租约的 Key 写入 etcd。
b. “心跳机制”:通过定时更新(类似心跳机制),确保 etcd 中始终维护网关中存活的全量 DP 节点信息。
2. 动态限流计算
a. 插件开发:新开发插件定时从 etcd 中拉取全量节点信息,获取网关节点总数。
b. 排除 CP 节点:通过特殊方式排除 CP 节点(控制面不承载流量),仅统计实际承载流量的 DP 节点数量。
c. 动态调整限流值:插件在限流时动态计算每个节点需要承载的限流基数,确保限流值与实际节点数量匹配。
3. 性能优化
a. 特权进程拉取:仅允许特权进程定期从 etcd 拉取网关信息,避免 APISIX 对 etcd 的压力,同时降低 APISIX 本身的开销。
b. 共享内存机制:特权进程将拉取的数据写入共享内存,其他进程通过定期查询共享内存获取节点信息。
4. 插件抽象与复用
a. 公共插件抽象:将动态限流优化能力抽象为公共插件,提供统一接口。
b. 插件复用:内部大量插件(如固定窗口限流、自定义性能插件等)可通过查询共享内存获取节点数,并动态调整配置,以适配优化需求。
分布式限流
接下来是分布式限流,APISIX 开源社区也提供了分布式限流方案。
问题描述
在应用开源分布式限流方案时,我们遇到了以下关键问题:
Redis 性能瓶颈:单 key 限流场景下,当限流规则针对整个路由而非路由特征时,Redis 的 key 会过于单一,导致所有请求集中到同一个 Redis 分片,无法通过横向扩容实现负载均衡。
网络性能消耗:频繁的 Redis 请求导致网关节点 CPU 使用率上升 50%+。
请求时延增加:开源分布式限流方案需先访问 Redis 完成计数,再将请求转发至上游,导致业务请求时延增加 2-3 毫秒。
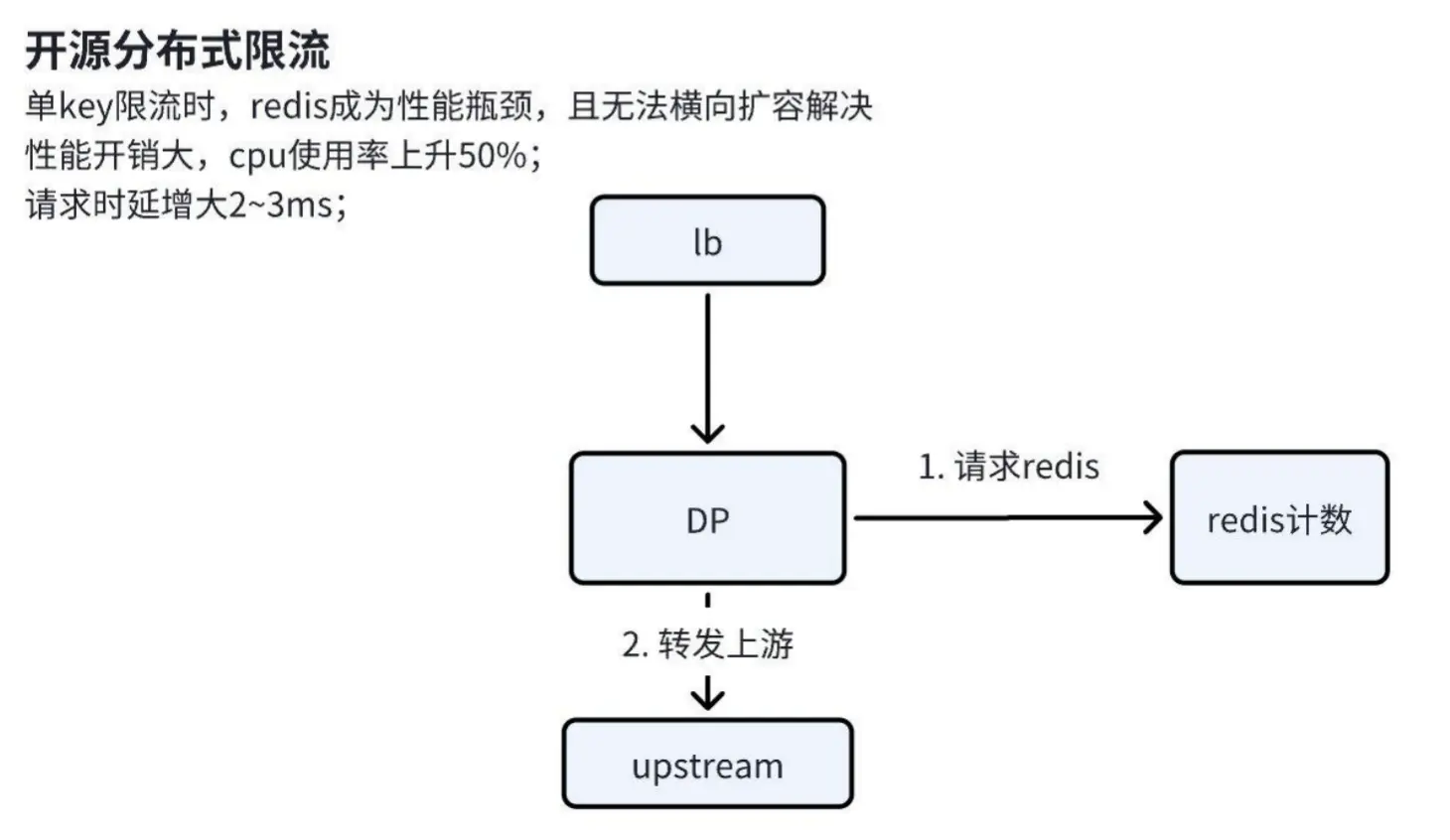
优化方案
为解决上述问题,我们设计了以下优化方案:
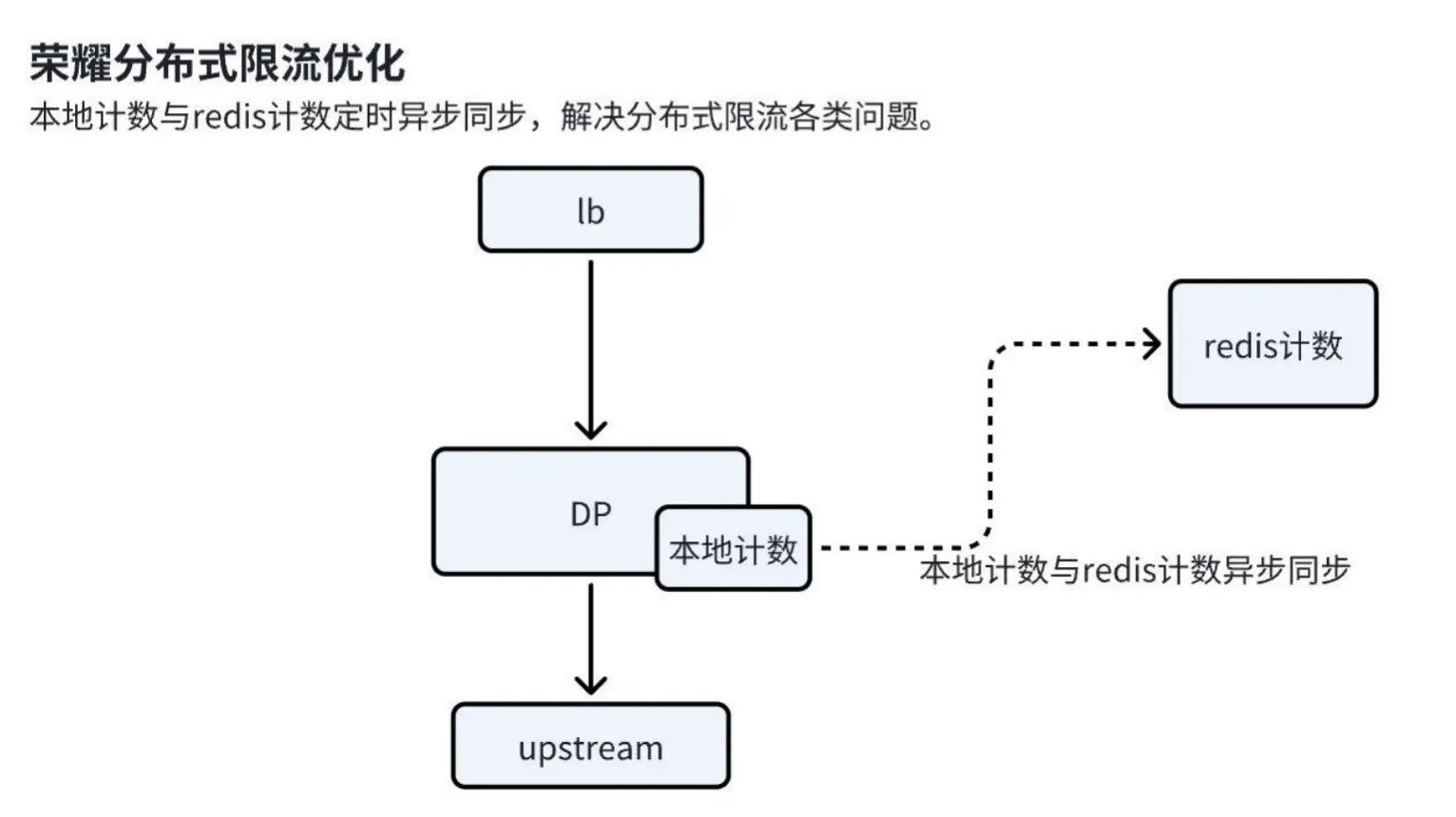
1. 引入本地计数缓存:
a. 本地计数机制:请求到达时,首先在本地计数缓存中扣除一个计数。只要计数未降至 0,请求即被放通。
b. 异步同步机制:本地计数通过异步方式定期与 Redis 同步,统计两次同步期间的请求量,并在 Redis 中扣除相应的计数。同步完成后,Redis 的计数覆盖本地缓存,确保分布式限流的一致性。
2. 误差控制:通过合理的公式计算和参数配置,将误差率控制在 3%-4% 的范围内,确保限流精度满足业务需求。
适用场景
- 高 QPS 应用:该方案适用于 QPS 较大的应用,能够显著降低 Redis 的性能瓶颈和网络开销。
- 低 QPS 应用:对于 QPS 较低(如几百 QPS)的应用,现有的分布式限流方案已基本满足需求,无需额外优化。
3.2 基于 APISIX 开发高可靠性的熔断插件
问题描述
尽管开源社区提供了熔断插件功能,但经过评估,发现其无法满足内部需求,主要体现在以下两点:
- 缺乏失败率支持:开源熔断插件的策略不支持基于失败率的熔断。
- 状态切换问题:熔断插件仅有开启/关闭两种状态,可能导致状态切换时放行大量请求,加剧上游服务恶化,甚至可能在上游响应超时时拖垮网关。
自研熔断插件设计
为解决上述问题,荣耀开发了基于 APISIX 的新熔断插件。其设计特点如下:
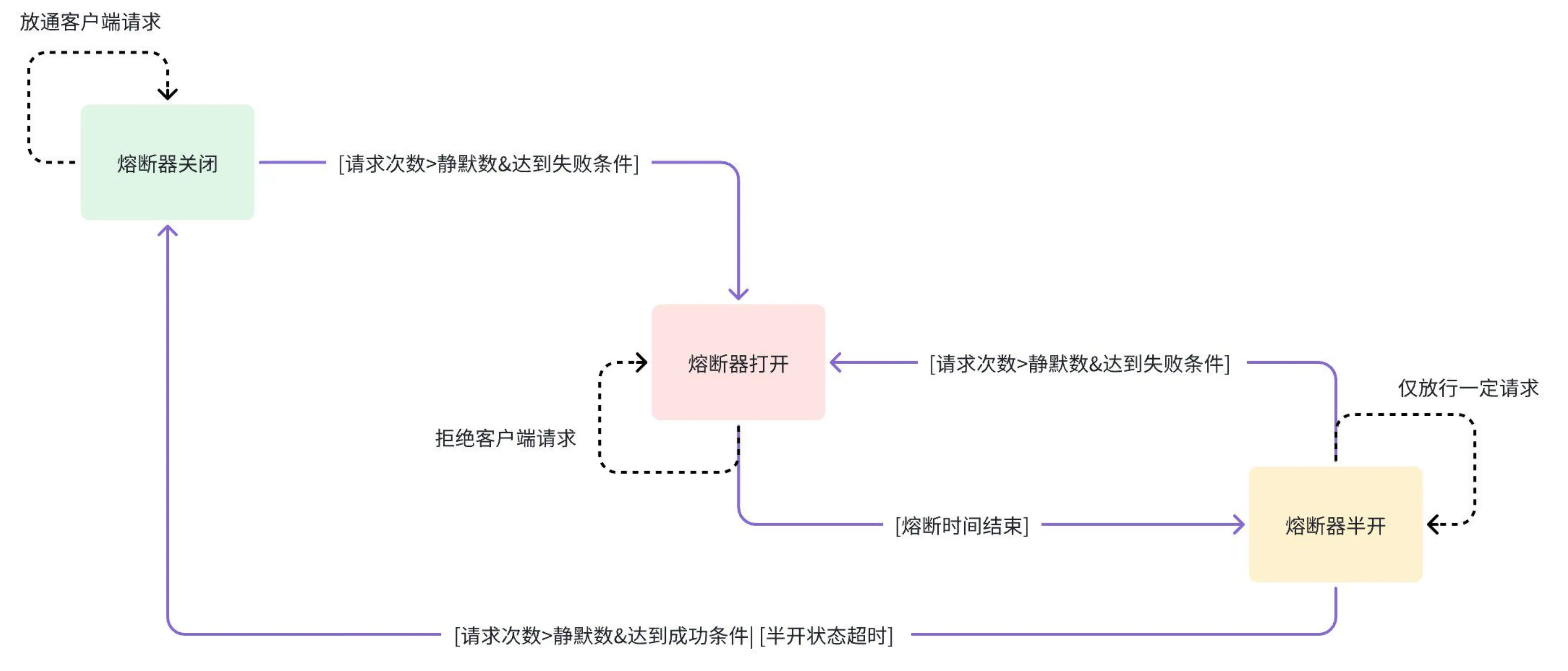
百分比熔断策略:支持基于百分比的熔断策略,提供更精细的控制。
三态控制机制:
a. 关闭状态:允许所有请求通过。
b. 打开状态:拒绝所有请求,直到熔断时间到期。
c. 半开状态:允许一定量的请求通过,用于评估上游服务是否恢复。
静默数机制:引入静默数概念,防止少量请求触发状态切换。只有当请求数量达到静默数且失败率达到阈值时,才会切换至打开状态。
状态切换流程
- 关闭到打开:当请求数量达到静默数且失败率超过阈值时,熔断器切换至打开状态。
- 打开到半开:熔断时间到期后,切换至半开状态。
- 半开到关闭:在半开状态下,若放行的请求数量达到配置值且上游服务恢复正常,则切换至关闭状态;若失败率仍高或无响应,则切换回打开状态。
基于 Sentinel 的设计更新
- 窗口机制:Sentinel 采用滑动窗口,而我们选择固定窗口,专注于时间内的失败率,简化实现并降低性能开销。
- 架构适配:针对 NGINX 的多进程架构,引入共享内存存储状态,确保各 worker 行为一致,同时避免滑动窗口带来的复杂性和性能损耗。
3.3 旁路 WAF 改造提升链路可靠性
串联式 WAF 的局限性
参考下图左侧架构图,传统的串联式 WAF 需要通过修改 DNS 记录将流量导向 WAF,WAF 清洗流量后再转发回源站。然而,这种架构容易导致单点故障。若 WAF 本身发生故障,可能导致整个链路中断,影响业务流量。
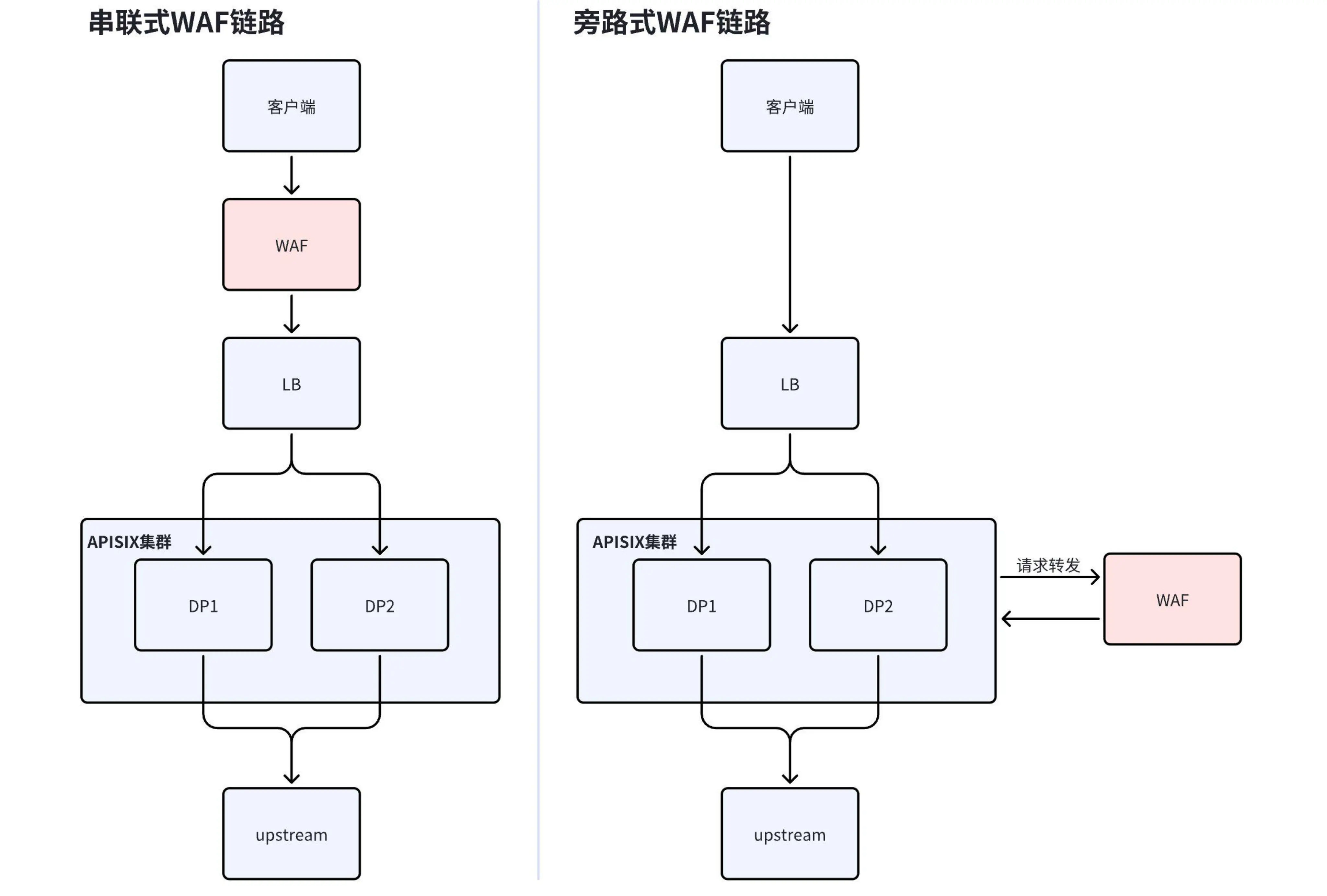
旁路 WAF 改造
为解决上述问题,荣耀联合支流科技和腾讯云进行了旁路 WAF 的改造:
流量路径优化:流量无需先经过 WAF,而是直接请求到 APISIX 集群。
分流量检测:在 APISIX 集群中,将部分流量转发至 WAF 进行检测,判断流量是否正常或是否包含恶意攻击(如出口攻击和命令出口攻击)。
状态码响应机制:
a. 若 WAF 检测到流量正常,返回
200状态码,请求被放通到上游。 b. 若 WAF 检测到恶意攻击,返回类似403的状态码,请求被拒绝。故障容错:若 WAF 发生故障,流量可直接转发到后端,避免因 WAF 故障导致链路中断,提升整体链路的可靠性。
性能与成本优化
性能优化
健康检查器优化
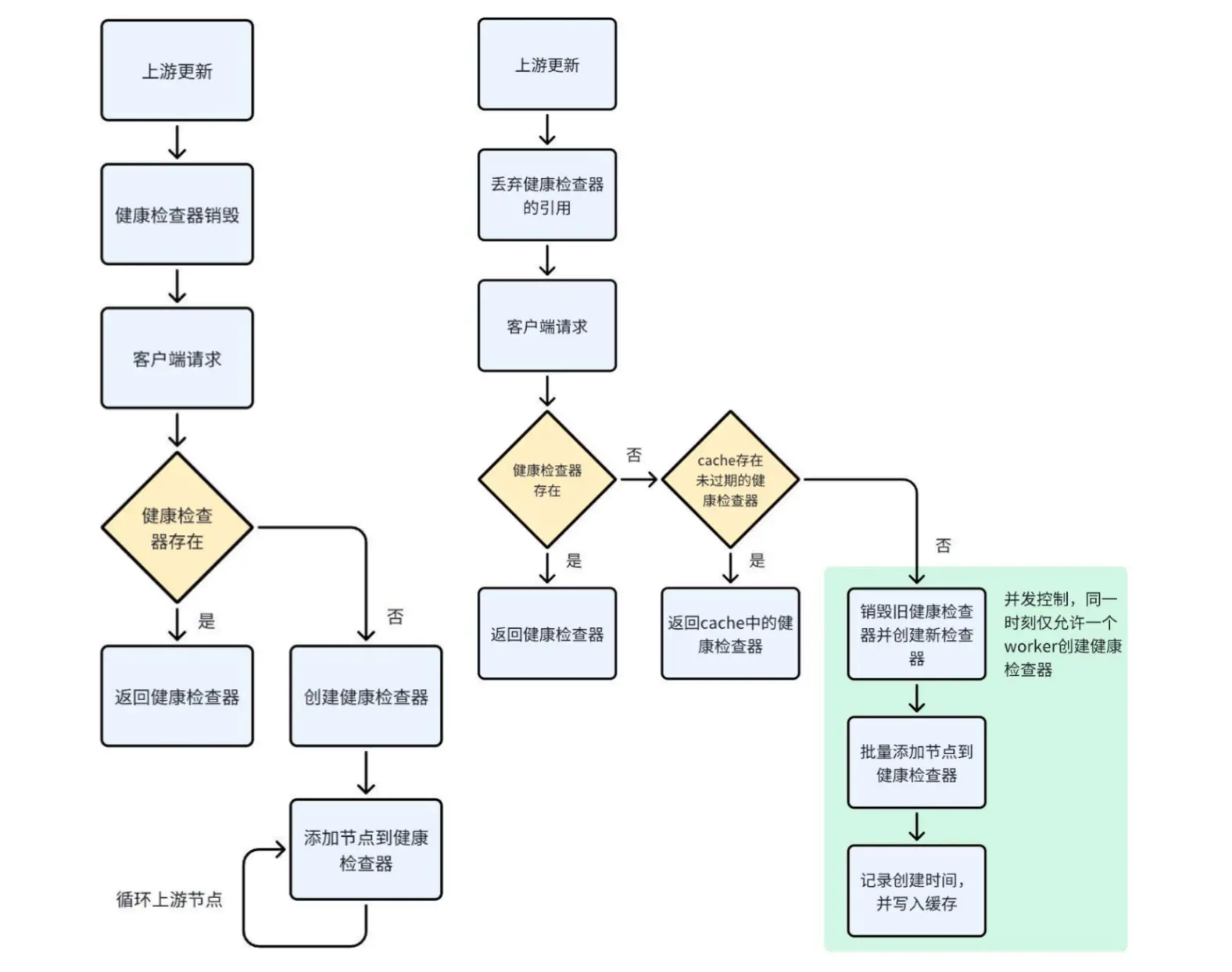
问题背景:内部业务流量较大,上游节点数量多(上千个节点),滚动更新时频繁触发健康检查器的销毁和创建,导致 CPU 使用率飙升。
问题描述:
a. 销毁与创建逻辑:上游更新时销毁健康检查器,仅在客户端请求到达时探测健康检查器是否存在,若不存在则立即创建。
b. 逐节点添加:创建时需遍历所有节点,逐个添加到健康检查器的共享内存中,涉及大量锁操作和内存写入,性能损耗显著。
优化措施:
a. 延迟销毁:在上游更新时暂时不销毁健康检查器,仅丢失引用,减少频繁销毁和创建的性能损耗。
b. 缓存机制:创建健康检查器时,将其放入缓存并记录创建时间。后续请求若发现健康检查器不存在,先补充缓存;若未过期则直接返回,过期则重新创建。
c. 批量更新:将所有上游节点批量更新到健康检查器的共享内存,减少逐节点操作的开销。
d. 并发控制:引入并发控制机制,确保同一时刻只有一个 worker 负责健康检查器的创建,避免多个 worker 同时执行相同操作,显著降低 CPU 消耗。
优化效果:在 2000 个上游节点的频繁更新场景下,优化后的 CPU 使用率仅增长约 2%,相比优化前的 20% 增长,性能损耗大幅降低,优化效果显著。
成本优化
成本优化主要包括三点:流量压缩、EIP 静态单线改造、网关扩缩容。
流量压缩
- 背景:经过对网关成本的统计分析,总体大约 3/4 左右的成本是流量成本。因此我们的优化首先需要针对流量。
- 优化措施:提供 br 和 gzip 等压缩插件,支持动态压缩。这种插件对于业务而言非常友好,只需在请求中加入压缩标识即可使用,客户端和浏览器通常支持解压操作。
- 效益:在云厂商的 LB 计费模式中,流量大小是最主要的计费因子。通过压缩插件降低 LB 费用和 EIP 带宽费用,最大压缩率可达 70% 以上,显著降低流量成本。
EIP 静态单线改造
背景:BGP EIP 的带宽费用高昂。
优化措施:
- 为网关集群配置电信静态单线 EIP,辅以兜底的 BGP EIP。
- 通过 DNS 智能解析,为主流运营商线路指定对应的单线 EIP。
效益:单线 EIP 的价格仅为 BGP 的 1/3,可节约约 2/3 的公网带宽成本。
网关扩缩容
- 优化措施:基于 CPU 和内存使用率进行网关的弹性扩缩容。
- 目标:确保资源利用率保持在合理区间,避免资源浪费或不足。
总结
荣耀自 2021 年引入 APISIX 以来,通过持续的优化与扩展,构建了一个高性能、高扩展性且可靠的网关平台,成功支持了海量业务的快速发展。
荣耀的网关平台经历了从试点推广到全量业务覆盖的演进过程,流量峰值达到数百万 QPS,并开发了近百个插件以满足多样化的业务需求。通过内外网协议优化、负载均衡器升级、插件市场建设等措施,提升了架构的稳定性和扩展性。在功能上,实现了灰度发布、限流、熔断、旁路 WAF 等优化,确保精准调度与高可靠性。性能方面,健康检查器优化和并发控制显著降低了 CPU 消耗。成本上,通过流量压缩、EIP 改造和扩缩容策略大幅降低费用。
展望未来,荣耀将继续探索 AI 与 API 网关的结合,进一步提升平台的智能化水平,并通过容器自动上报机制等创新手段,助力内部团队在 Kubernetes 环境中实现高效的资源管理和业务部署。