In this article, Zhang Qiang, head of SRE network in WPS, explains how WPS can use Apache APISIX to handle Mega QPS, and update and improve gateway practices based on Apache APISIX.
Background
WPS is currently the largest domestic office software manufacturers, its products include WPS Office, Kdocs, Docer and so on. At the business level, deployed by thousands of businesses in a container on an internal cloud native platform, Apache APISIX at WPS is currently responsible for providing gateway services to the mid-stage business (Mega QPS) .
Gateway Evolution in WPS
In phase 1.0, we didn’t have a strong requirement for API Gateway features, we just wanted to solve the operations problem, so we did our own research based on OpenResty and Lua to implement dynamic Upstream, blacklist, WAF and so on. Although self-developed, but left some problems in the function, such as:
- It’s only as dynamic as the Upstream dimension
- Need to Reload to bring out the new domain name
- The bottom design is simple, the function expansion ability is not strong
Following the strong demand for API Gateway functionality, we began to investigate the related open source Gateway products.
Why Apache APISIX?
In fact, when the research on gateway products began in late 2019, Kong was one of the more popular choices.
However, subsequent tests showed that Kong’s performance was not quite up to our expectations, and we didn’t think that Kong’s architecture was very good: its configuration center used PostgreSQL, so Kong can only use the non-event driver to update the route, relying on each node to refresh the route.
On further investigation, we discovered Apache APISIX. First of all, Apache APISIX performs better than Kong, and there’s a very detailed graph in Apache APISIX’s GitHub Readme that shows the performance of Apache APISIX Compared to Kong, which are basically consistent with the data we’ve tested ourselves.
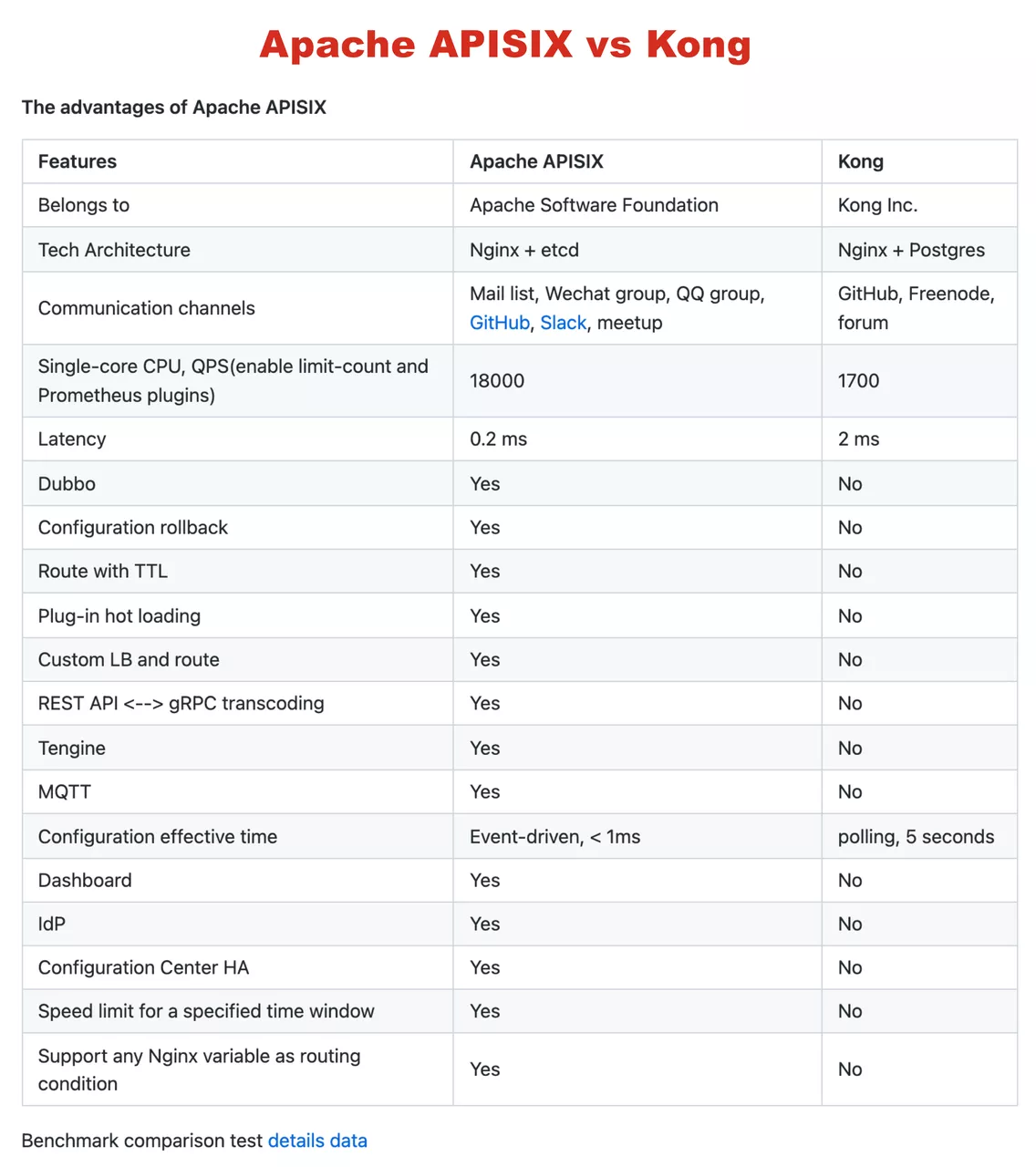

In terms of architecture, Apache APISIX’s ETCD configuration is a better choice for us.
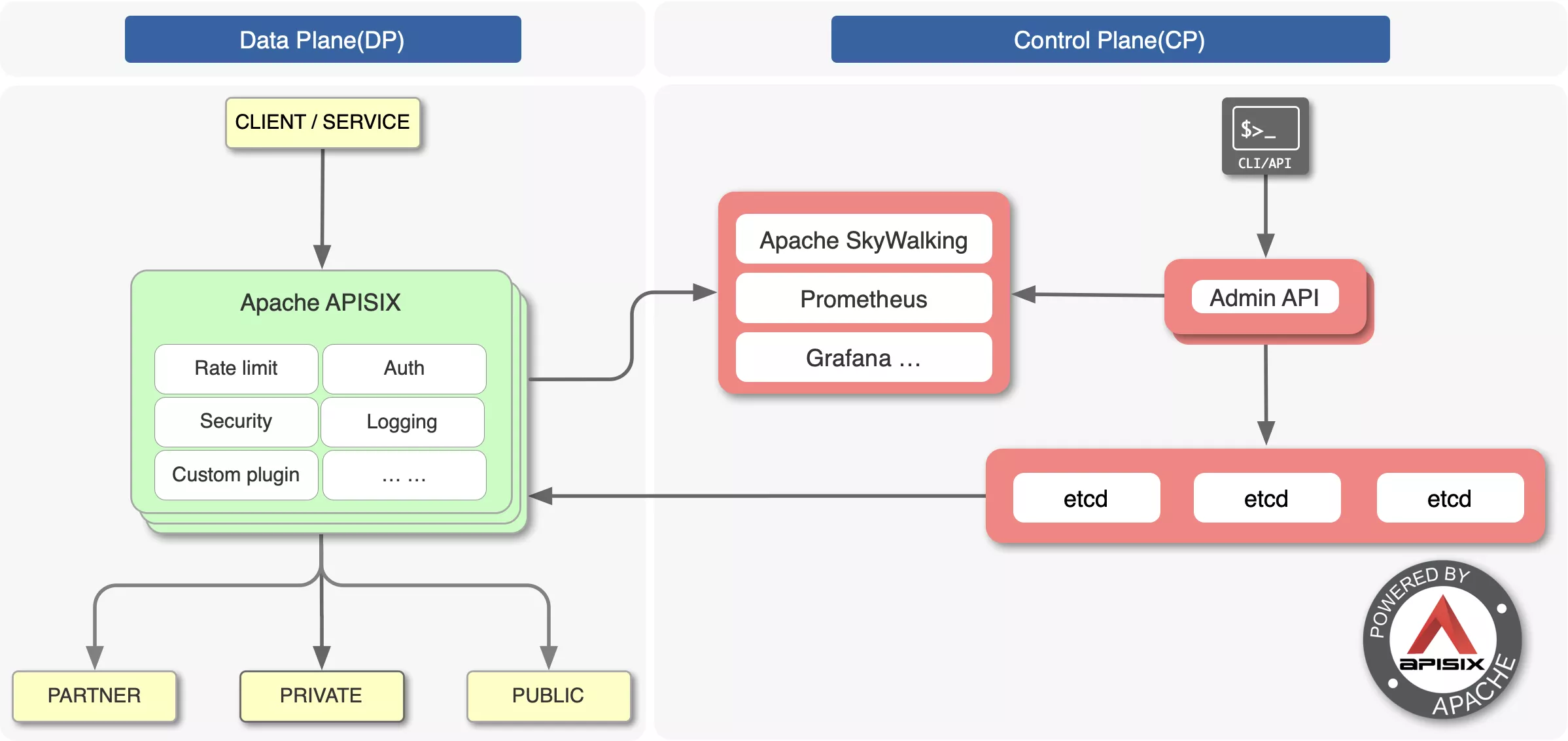
The main reason, of course, is that we feel that community is also important. If the community is active, it will be able to update iterations, troubleshoot problems, and optimize functionality quickly. From GitHub and regular email feedback we can see that the Apache APISIX community is active, providing a strong guarantee of product functionality and stability.
Experience of Gateway Smooth Migration
When most of my friends started working with Apache APISIX, they used the CLI to generate configurations and instances. However, during our smooth migration, we did not use the CLI to generate the configuration.
The main reason is that Apache APISIX does some Phase in OpenResty, such as initializing the init, init_worker, HTTP, and Upstream related phases.
Corresponding to the Apache APISIX configuration, we found that these can be migrated from the CLI smoothly.
So for these reasons, we ended up doing the following smooth migration:
- CLI generation configuration without Apache APISIX
- Introduce a Package Path for Apache APISIX and make Apache APISIX the Default Server
- KEEP domain names in other static configurations, and because the new domain name is not in the static configuration, Fallback to Apache APISIX
- Eventually the static configuration was migrated gradually to Apache APISIX
Of course, in addition to the above, we recommend a “Light-mixing mode” that uses static configuration with Apache APISIX as Location, with some of the Phase or Lua code mentioned earlier. Doing so allows you to introduce special configurations into your static configuration, make it dynamic, etc. .
Shared State Improvements Based on Apache APISIX
First of all, in my opinion, “The Shared State is the biggest factor in the stability of the feed, which is definitely not an issue.”Why?
Because forwarding efficiency can be addressed by scaling laterally, the Shared State is a critical module because it is Shared by all nodes.
So after using Apache APISIX, we made a few tweaks and optimizations to focus on the Shared State layer.
Improvement 1: Optimize ETCD Architecture with Multiple Machines Listening
In a typical corporate gateway architecture, multiple machines are involved, some as many as a few hundred, and each machine has to take into account the number of workers. So when multiple machines monitor the same Key, the pressure on the ETCD is greater, because one of the ETCD mechanisms is to ensure data consistency, requiring all events to be returned to the listening request before new requests can be processed, the request is discarded when the send buffer is full. So when multiple machines listen at the same time will cause the ETCD to run overtime, Overload error, and so on.
To solve the above problem, we use our own ETCD Proxy. The previous connection between Apache APISIX and ETCD is shown on the left side of the figure below, with each node connected to the ETCD. So as a large-scale entry, the number of connections can be particularly large, putting pressure on the ETCD.
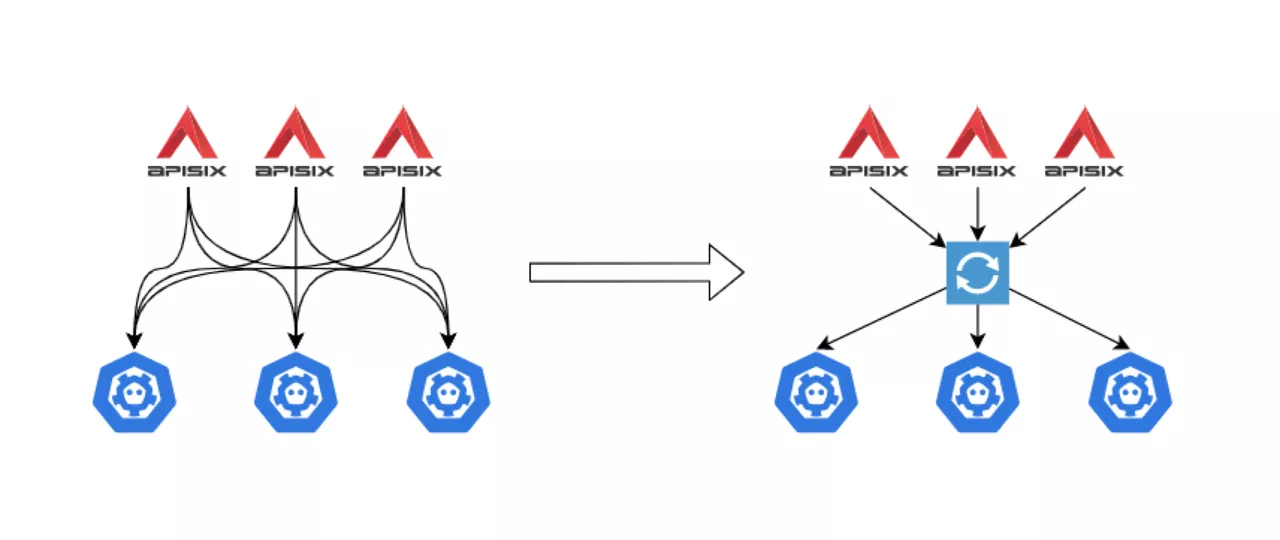
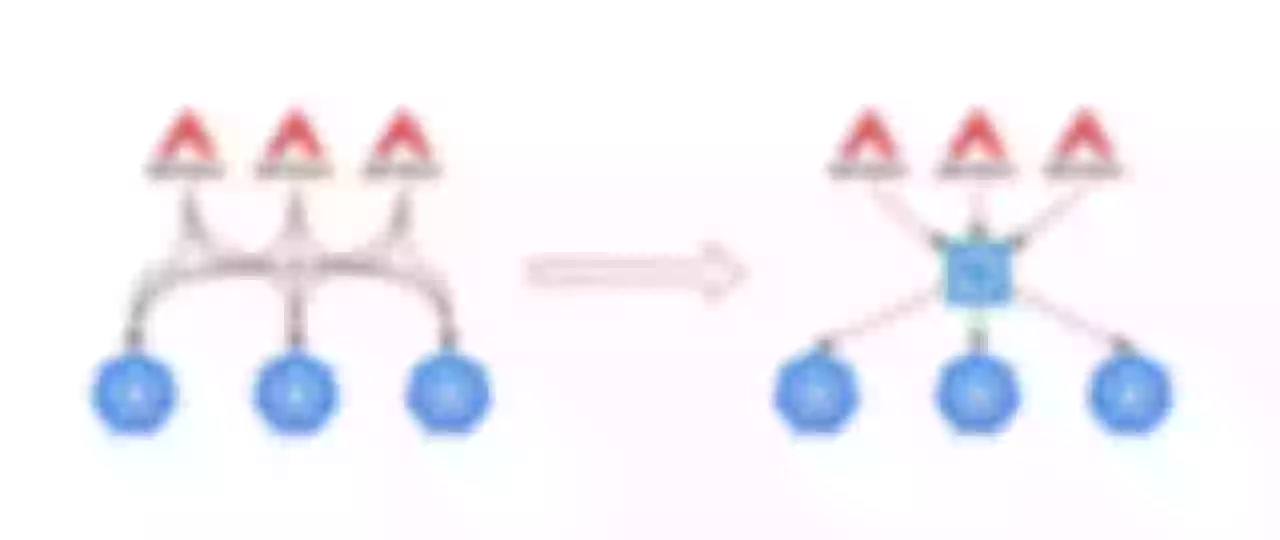
Since we are listening to the same Key, we make a proxy to do a uniform listening and return the results to Apache APISIX when there is feedback. As shown on the right side of the image above, the ETCD Proxy component is placed between Apache APISIX and ETCD to monitor changes in Key values.
Improvement 2: Solve the Performance Problem During Routing Validation
As companies grow in size, so will the number of routes. In practice, Apache APISIX reconstructs the prefix tree used to match the route each time the route is updated. This is mainly due to poor sort performance of table.sort.
In the process of practice, we observe that the CPU of the gateway increases and the packet loss rate increases when the route is updated frequently.
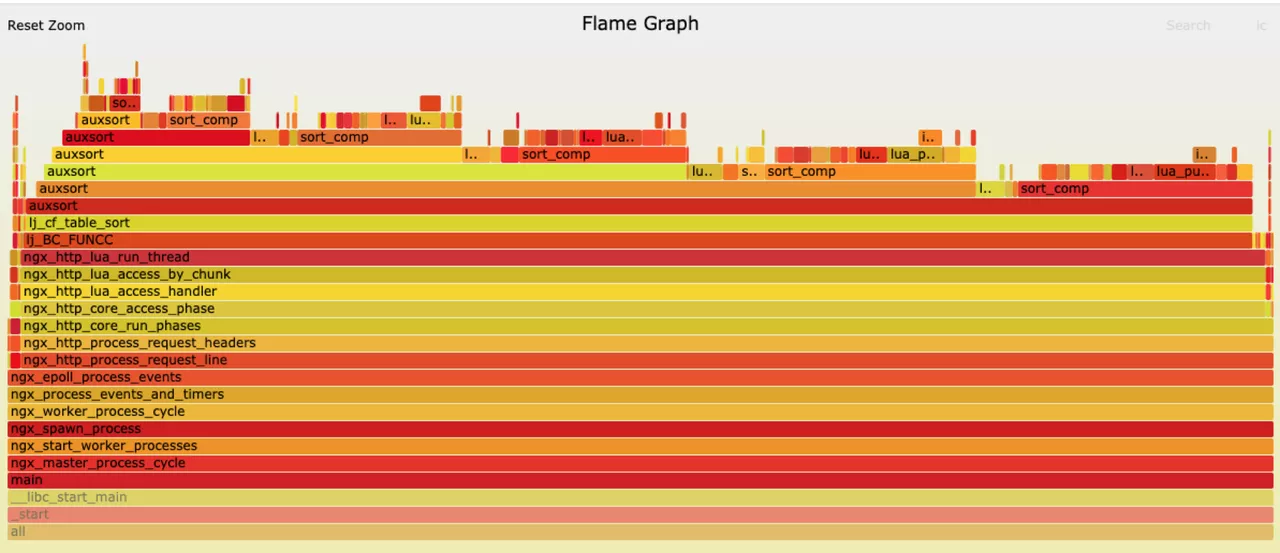

In terms of CPU ramp-up, it is clear from the flame diagram that the majority of CPU time is allocated to the auxsort, which is triggered by FUNCC. The FUNCC trigger also points to the problem of proving that the data did not pass through Luajit and that only the rightmost part of the graph processed normal requests.
The main reason for this is LuaJIT’s table.sort doesn’t rely entirely on the JIT mode, as you can see in the Luajit wiki, so it works in the Lua code environment with low efficiency.


We solved this problem ourselves using pure Lua code to implement the sort configuration for the above scenario, but Apache APISIX has since fixed the problem, the idea is similar to what we understand.
More Experience with Shared State
- When you modify Apache APISIX or do your own plug-in development, make sure you do Schema validation, including nulls, especially in the matching section. Because if something goes wrong in the matching section, it can have an impact on the whole.
- Do a good job of business split planning. Plan your ETCD Prefix and IP numbers according to your traffic, and deploy more robust clusters to minimize systemic risks.
Open Source Discussion
The Trade-off Between Stability and Function
WPS has been using Apache APISIX for almost two years now, and as a product user, I think Apache APISIX is really a stable and reliable open source product, keep up to date with the latest community releases.
But as anyone who has ever used an open source product will know, there will be some new features in the updated version, but there will also be some stability issues, so how do we choose between the updated version and the stability.
There is no universal answer to this question, but I personally feel that for Apache APISIX, try to keep up with the official version.
As far as the Jinshan District Office is concerned, we currently have a very high level of stability due to the large-scale use of Apache APISIX. We’ve had some trouble keeping up with the official updates, so we recommend keeping up with the official version as much as possible.
If you’re like the rest of us, you may not always be able to keep up with the official version, but you should at least be able to check out GitHub’s Master Change Log and other documentation on a weekly basis and keep an eye on product changes.
Based on Apache APISIX Production Experience
Based on Apache APISIX, we have packaged a number of product features, such as multi-room application scaling, one-click blocking routing, and so on. In practical application, we realize that Apache APISIX is a very flexible and powerful product, so we should understand one point when we make the transition to production: powerful = unavoidable complexity and danger.
Apache APISIX itself has a lot of code design, for example, some plug-ins may need to be modified to compile their own, because after all, the respective application scenario can not be unified.
Finally, based on the practical experience mentioned above, it is also recommended that the granularity of gateway sharing should be planned well in advance to reduce the problems of subsequent use.