This article will bring you about how Airwallex uses Apache APISIX for gateway layer deployment to strengthen the construction of data sovereignty.
Why deal with data sovereignty?
Airwallex is a global financial technology company that helps global users with payment services and cross-border payment scenarios. A global financial infrastructure platform has been built, and the payment network has covered more than 50 currencies in more than 130 countries and regions around the world, providing enterprises with digital financial technology products.
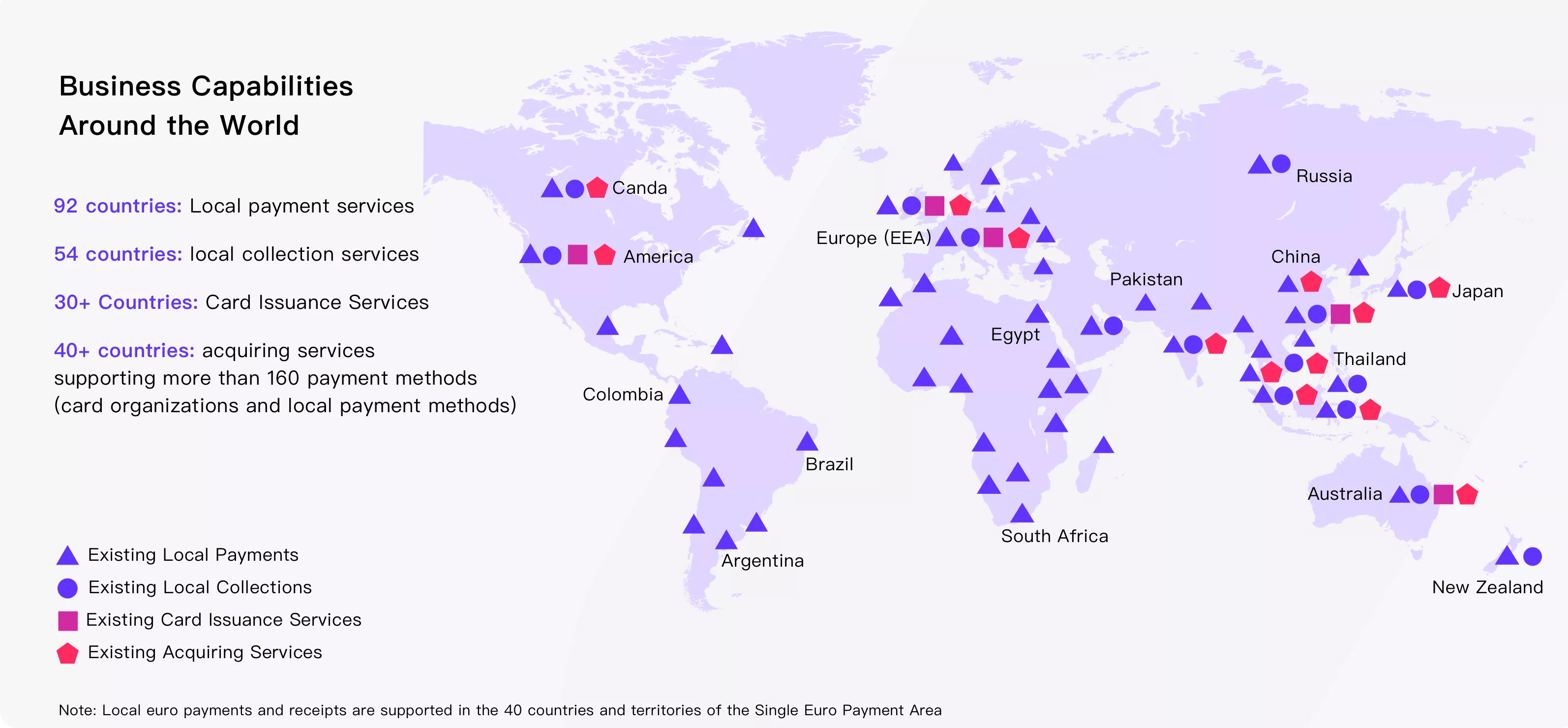
Under the demand of global service content, the risk of data sovereignty must be considered in the conduct of the company's business.
What is data sovereignty?
Data sovereignty refers to the national sovereignty in cyberspace, which reflects the status of the state as the subject of controlling data rights. Before describing the importance of data sovereignty, let's give a few examples.
GDPR (General Data Protection Regulation) is a regulatory document formulated by the European Union, which is aimed at the privacy and protection of personal data. One of the most basic requirements in GDPR is that all user data collection activities need to be approved by the user, while ensuring that the user can clear personal data on their own.
Therefore, if the Airwallex wants to transfer European data to other regions, it must ensure that the requirements of third-party countries on data sovereignty meet the requirements of the European Union on data sovereignty. With regard to the need for data to comply with local laws, there are indeed a lot of concerns in multinational operations.
For example, the American Patriot Act requires all data stored in the United States, or data stored by American companies, to be regulated in the United States, and the US Department of Justice and CIA can require companies to provide data.
After 9 / 11, 2013, the Justice Department asked Microsoft to provide some of the email information it stored on its servers in Ireland, when Microsoft rejected the request on the grounds that it would violate EU regulatory requirements. Then the U.S. Department of Justice took Microsoft to court, but Microsoft won in the end. Later, in order to avoid the risk of the opposite of data sovereignty, many American companies put their data centers directly to Europe, thinking that it would be safe. But in some recent cases, judges have ruled that the United States still has the authority to ask for data from American companies in Europe.
Judging from the above events, data sovereignty has indeed brought great challenges to Airwallex's global business, and how to properly handle the issue of data sovereignty in the business has become particularly important.
Current situation of transnational business data transmission
Because the business involves transnational attributes, some problems will be encountered in the technical processing.
The data flow of multinational corporations is reflected in a variety of interactions between different regions. In the absence of data sovereignty claims, the data can be stored in Europe and then Synchronize to any data center in Asia or the world. When you make a subsequent data service request, you only need to encapsulate the business into a service.
But in the current era of emphasis on data sovereignty, the above approach will not work. Because the flow of a lot of data is beginning to be controlled, the previous architecture cannot be used. Domestic data can only be processed locally, not transnational requests. So when we store user data in the user's home scope that is, the "closed alone" architecture in the following figure), problems begin to emerge.
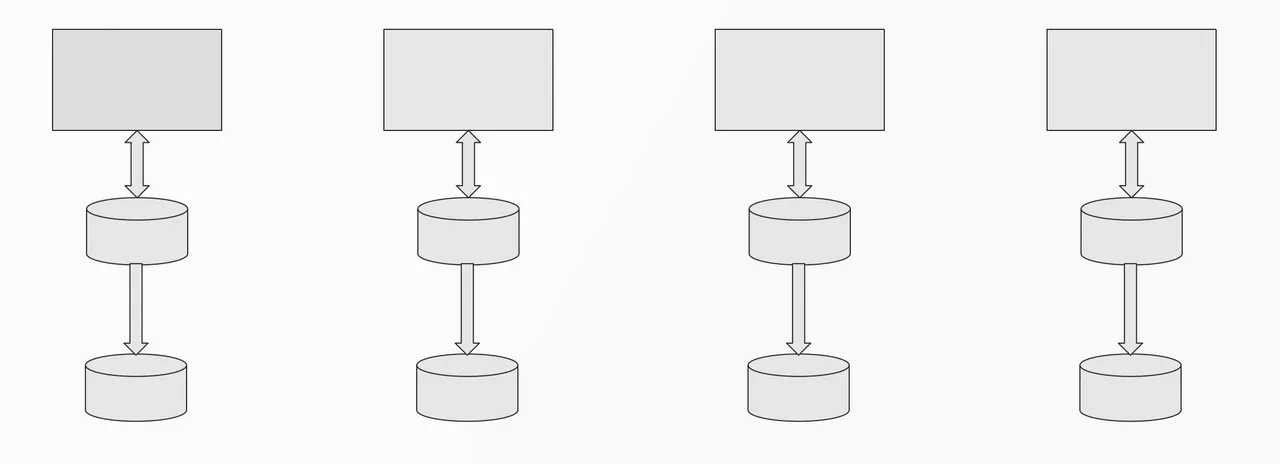

First of all, it is impossible to make the service completely stateless in this case, and most of the scenarios are not that simple in real business. Because the completion of the business, it is bound to involve the interaction between multiple clusters.
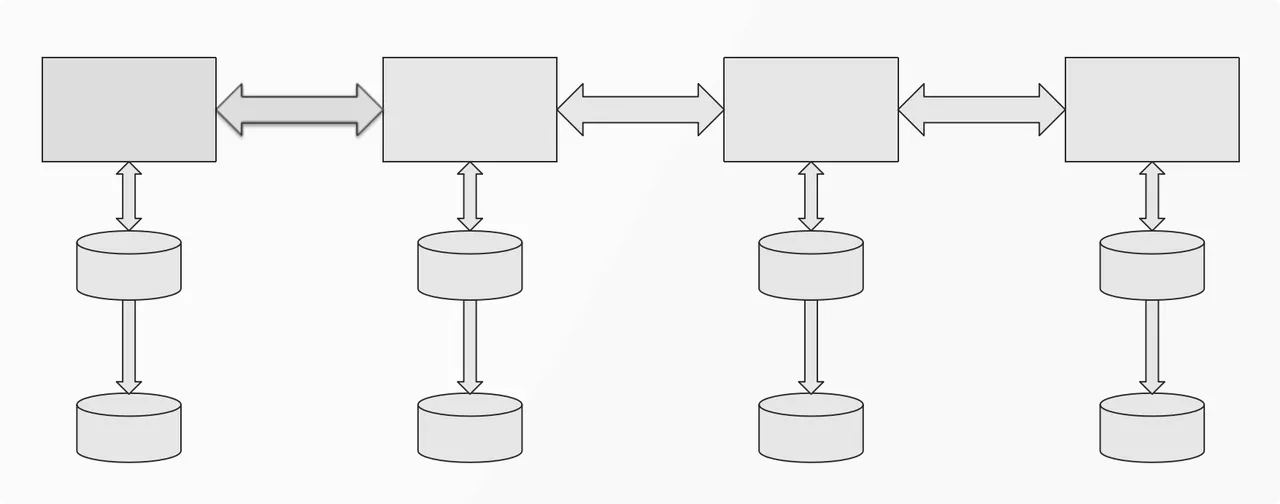

Therefore, in the aspect of data storage, the first problem to be solved is the region / region identification configuration at the data entrance. Just like Amazon, e-books purchased in the United States cannot be downloaded to their own Kindle using their national accounts. Because the data between countries (regions) is completely isolated. As long as users click on Amazon China, it means that all your requests will not step out of the Chinese data center.
Amazon's mode of operation actually allows users to decide where to store their personal data, but the resulting problem is that in the case of single-person and multi-regional accounts, it is very inconvenient for individual users to manage and Synchronize.
Therefore, for business processing in multi-regions and multi-scenarios, we should also need a "sharp weapon" to dynamically allocate and determine the direction of the follow-up data.
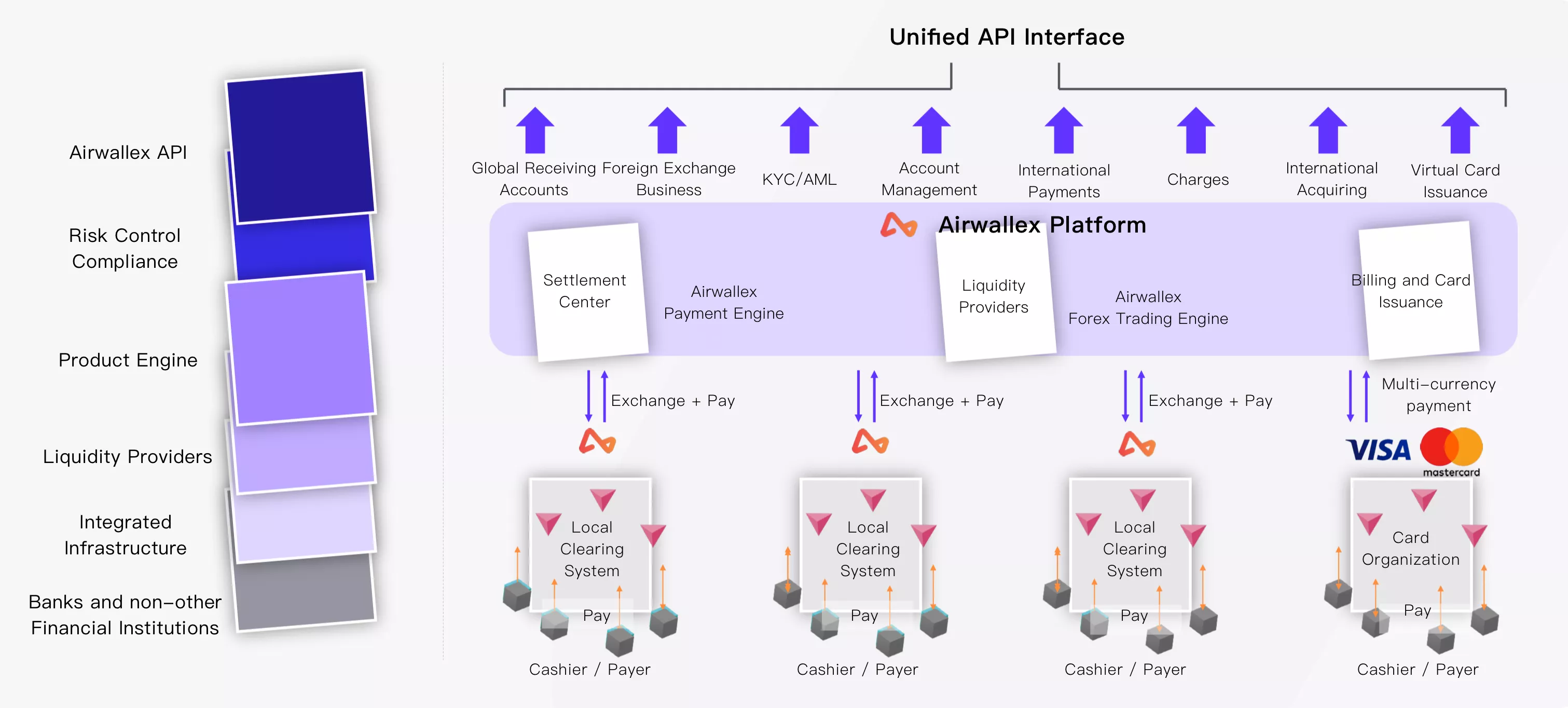
Building Apache APISIX Intelligent routing Gateway
Therefore, based on the above business scenarios, we decided to adopt the "intelligent routing" mode, through the gateway to determine the foothold and direction of different types of data requests.
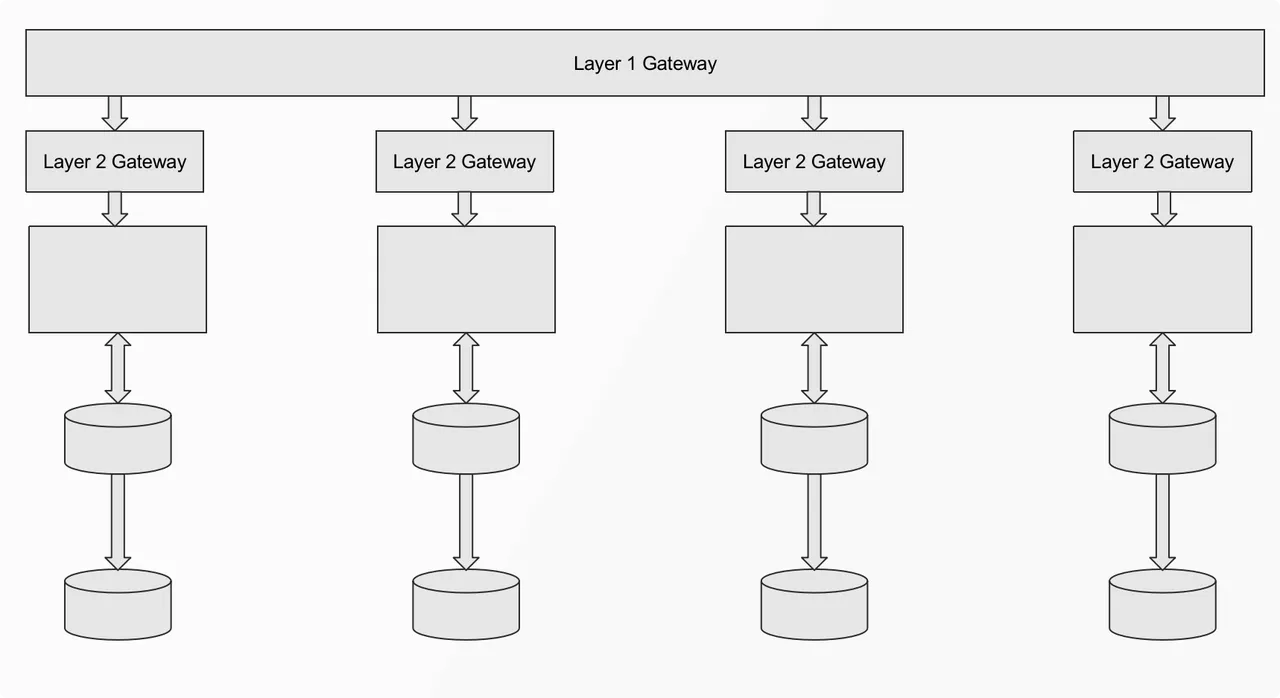
The above figure is the architecture diagram in "intelligent routing" mode. The gateway is mainly divided into two layers, the first layer is responsible for routing requests, according to the conditions to determine which data center the request should reach, and the second layer gateway is for traffic forwarding. Therefore, the main problem solved by the gateway in this mode is to assign a "destination" to each request, and then carry out subsequent traffic forwarding and business processing.
Currently, in our business scenarios, traffic information is mainly divided into two categories:
Unidentified request:
- Registration: the information is incomplete when a user registers for the first time, and he / she does not know which data center the user's registration data is in.
- static resources: for example, HTML, CSS, etc., you do not need to know the identity of the user.
Known identity request:
- Login: the user logs in, indicating that the registration process has been completed, and the location of the data center is known at this time.
- password reset: you can check where the data is through user name, mobile phone number, mailbox, city and other information, and then distribute subsequent requests
- Business operations in complex scenarios
In the deployment at the gateway level, we use Apache APISIX. Next, we will briefly introduce how to deal with dynamic, multi-data center routing scenarios based on Apache APISIX's API gateway.
Scenario 1: login and password reset
We can get the user name and password when the user logs in, but the password cannot be used as identification information, and it is not allowed to be passed casually. Therefore, it can only be queried according to the user name to determine which region the user belongs to. Business is the need to design a global Synchronize data storage.
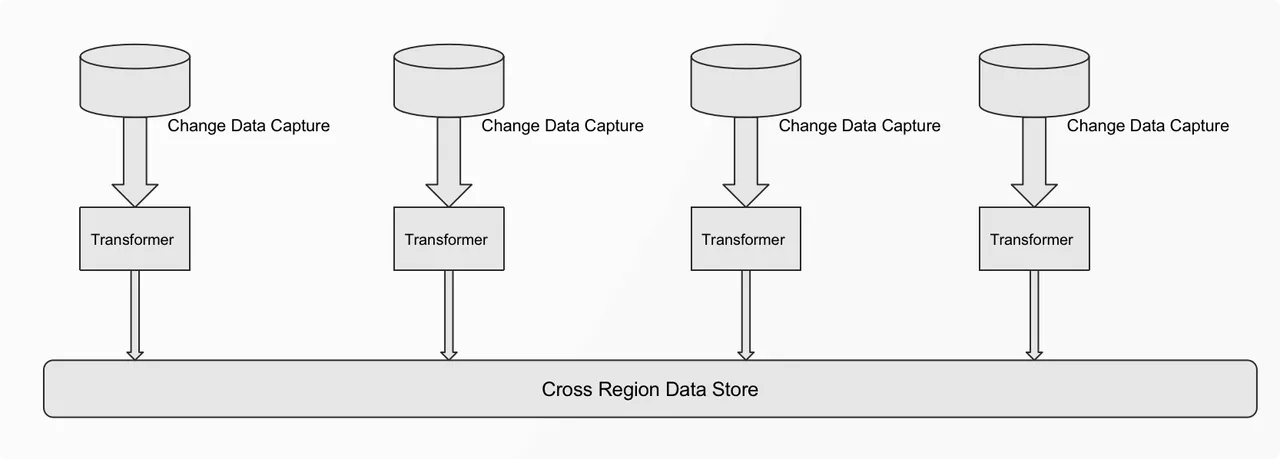
In this case, we have carried out the data storage architecture shown above, which can ensure the globalization of data Synchronize. For example, when a user registers an account in China, we convert the relevant data into Kafka message, through CDC (Change Data Capture) and receive local messages through a special listener, and then make further conversion. For example: excluding user name, Email and other personal information, these information can not be stored across borders.
In the process of converting (Transformer), salt or hash encryption can be carried out, and finally, the relevant business requests can be processed at the gateway layer, that is, data area allocation and subsequent traffic forwarding. Realize the business processing based on the Apache APISIX gateway level.
Scenario 2: business operations in complex scenarios
The business operation is that when I manipulate a piece of data, how should I decide where the data is going to be executed. Conventional business operations, such as a user querying his own account information or history, are generally divided into two modes.
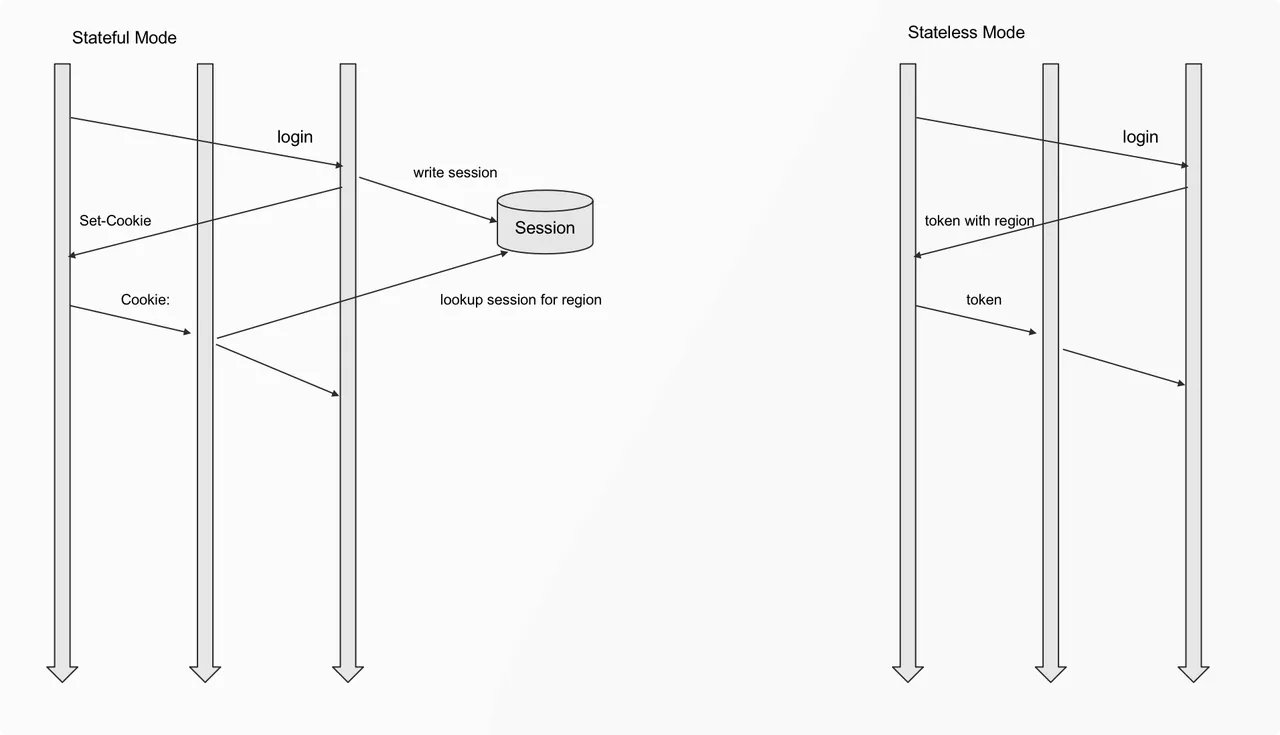

Stateful Mode
Stateful mode generally makes use of Session (as shown on the left side of the figure above). After the client has logged in, Sever will give the Cookie with Session ID to the client. Upon request, the gateway layer implemented based on Apache APISIX uses the information in Cookie to query the user's region. Even if the user changes the server, the login status can still be maintained, and the system can also determine where to get the data.
For example, users are traveling across borders, initially logging into the system in Europe and flying to Asia. When logging in in Asia, the system will determine which data center the user information is in through Session, and the request will be distributed to the corresponding data center for subsequent business operations.
Stateless Mode
Usually we will not only provide web access, but also have some API access to integrate. Therefore, when making API access, the way to pass Session ID through Cookie is not appropriate. In this case, we use a special Token (as shown on the right side of the figure above). The Token contains specific information about the data center so that Apache APISIX can decide which data center to access based on the Token.
The advantage of this is that it can remain dynamic when the business is expanded later. If the initial design is static and the data center is determined based on the information at the time of the initial registration, it will be very difficult to deal with cross-data center scenarios in the future.
There is also a more complex scenario in stateless mode, which is user registration. Because when registering, you can only decide which data center to put in according to the registration information filled in by the user. But if the user emigrates later, or the company migrates somewhere else, we have to clean up the relevant data and migrate all the user's transaction data, user name, password and so on to another data center. This kind of data switching cost is actually relatively high.
At present, we also support complex scenarios such as users switching data centers, but we will also start to consider how to reduce the impact of switching data centers on the overall architecture.
Attitude about data sovereignty
In fact, everything we mentioned above illustrates one problem, that is, "data and location". However, before the division of data ownership, there is a very important premise, that is, the degree of information processing.
The data is sensitive, and when we get user data for data analysis/commercial BI or other big data analysis, we can't use it immediately. We should first carry out the Filter of sensitive information at the personal level, in addition, at the data aggregation level, when the data from the same region are aggregated to look at the overall data, and then abstract the user information again, so as to achieve the state that the user can not be fully identified.
Only in this way can we meet the regulatory requirements and use this information for data analysis. This is the most fundamental requirement of data processing. While we standardize data supervision, we should also ensure the "security" of user information.
Of course, the shared Apache APISIX based gateway-level processing of data sovereignty is only part of the process of "dealing with the risk of data sovereignty". We expect the Apache APISIX gateway to help Airwallex do better and better at the level of data sovereignty, and so far, Apache APISIX has done what we expect.