
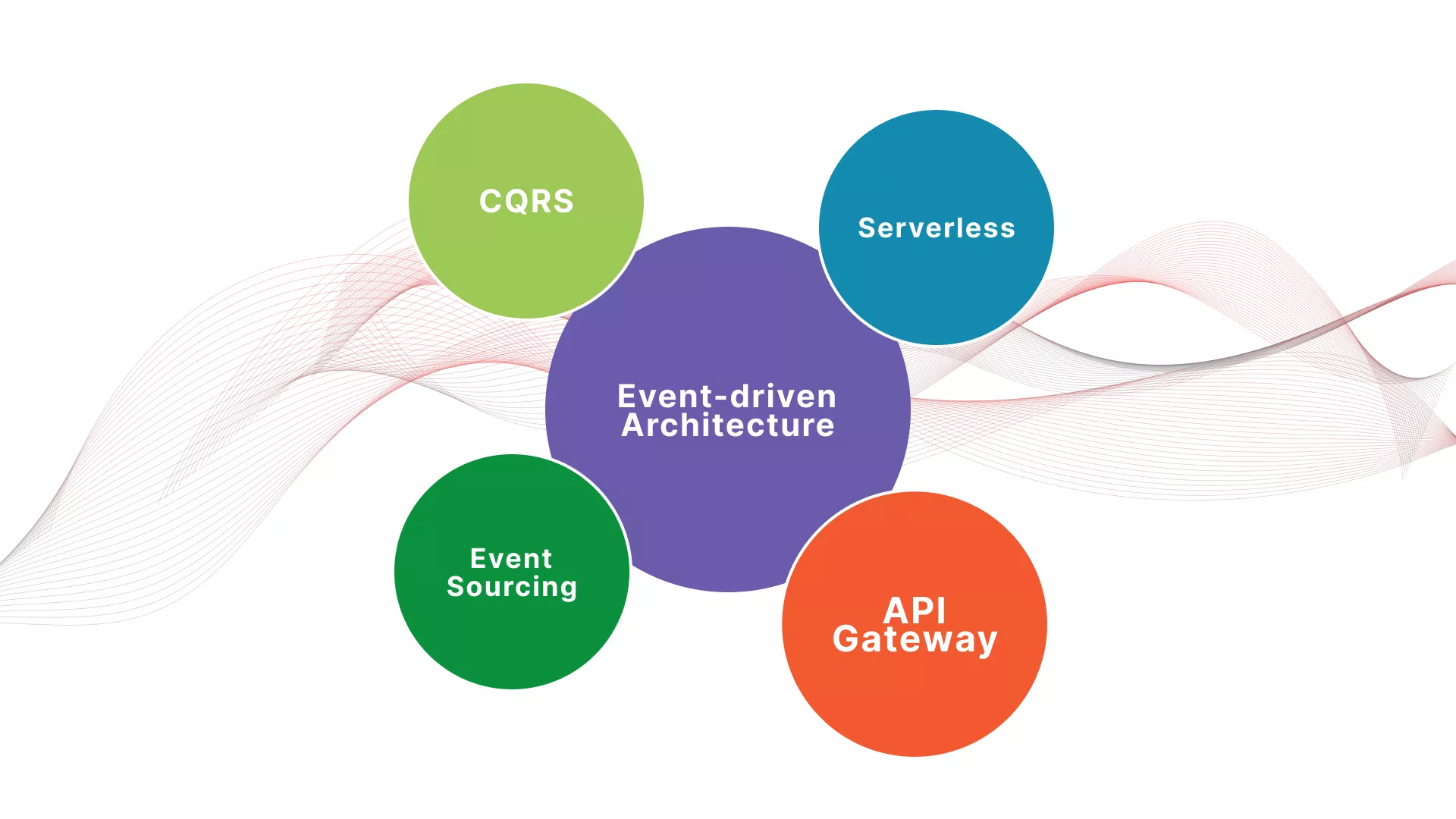
This blog post explores how to build event-driven API Services using these 3 well-known patterns to build a highly scalable and distributed system. We will break down each concept and understand the role of each in our particular approach.

Developing API services using CQRS, API Gateway and Serverless combine three patterns, using the command query responsibility separation (CQRS) pattern, the event sourcing pattern, and the API Gateway pattern. The CQRS pattern separates the responsibilities of the command and query models. The event sourcing pattern takes advantage of asynchronous event-driven communication to improve the overall user experience. Furthermore, an API gateway should also be implemented as a resource router, thus preventing API consumers from having to deal with different URLs depending on the action being performed.
Although the three concepts are independent, they complement each other well. This blog post explores how to build event-driven API Services using these 3 well-known patterns to build a highly scalable and distributed system. We will break down each concept and understand the role of each in our particular approach.
The event-driven architecture
An event-driven architecture makes use of events to trigger and communicate between decoupled services. Each service publishes an event whenever it updates its data. Other services subscribe to events. When an event is received, a service updates its data.
This architecture has several benefits such as you completely decoupling producer and consumer services. If one service has a failure, the rest will keep running. Consumers can respond to events immediately as they arrive. It adds agility as well. If you want to add another service, you can just have it subscribe to an event and have it generate new events of its own. The existing services don’t know or care that this has happened, so there’s no impact on them.
Why not use simply CRUD
Usually, we use the same data model to query and update a database that is similar to the basic CRUD operations (“CREATE”, “READ”, “UPDATE”, and “DELETE”) and it is the most straightforward way of dealing with data manipulation. We can build API services by following this simple principle. Any tool or framework that advertises itself as a quick method to bring your application to the market. But modern applications involve more complex business processes with workflows, validation, and business logic that are difficult to express using the classic CRUD paradigm.
Some of the following challenges you can think of:
⛔️ Since for both read and write operations, and the same DTO or data transfer object are used, there’s a chance that read and write operations will be out of sync.
⛔️ The application can perform a majority of reading queries (for example, searches) where your logic is not optimized for only read operations.
⛔️ As both read and write activities are permitted, security and permissions become more complicated to manage.
⛔️ Different data representations are required in order to address the multiple API consumer needs.
As a result of these difficulties, a new set of data manipulation patterns known as CQRS has arisen to enhance the classic CRUD methodology.
CQRS
CQRS stands for Command and Query Responsibility Segregation, a pattern that separates reads and writes into different models, using commands to update data, and queries to read data.
This CQRS pattern, as it is known today, was first introduced by Greg Young and was inspired by Bertrand Meyer's command-query separation principle. Since its introduction, the pattern has gained a lot of popularity, and several resources can be found online describing its many flavors. This link is a good source describing Young's original thinking behind the pattern.
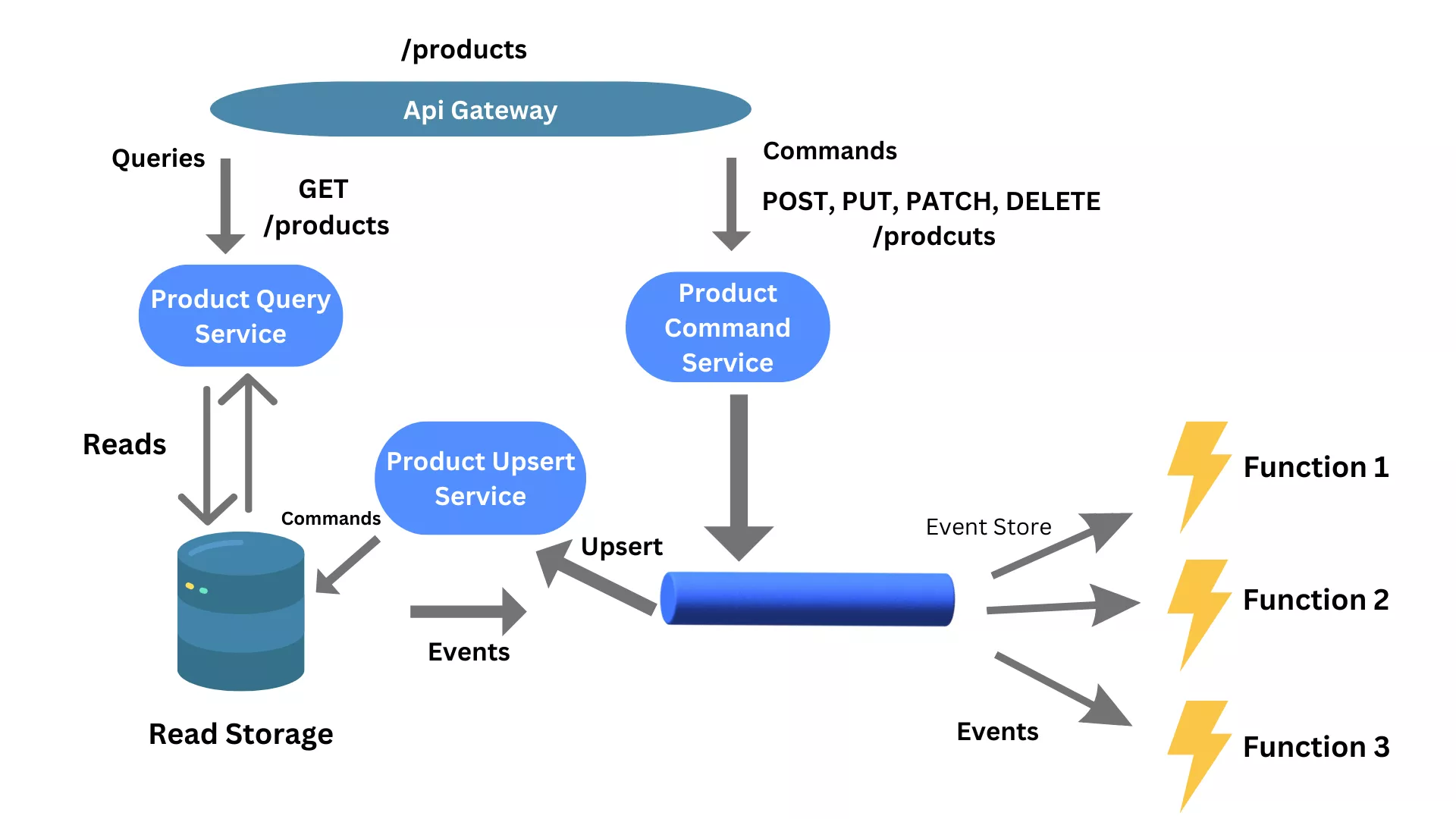
This pattern helps, as instead of having a standard service and storage supporting traditional CRUD operations, query and upsert (updates or creates) responsibilities are split (segregated) into different services, each with its own storage. Technically, this can be implemented in HTTP so that the Command API is implemented exclusively with POST routes (The write side uses a schema that is optimized for updates), while the Query API is implemented exclusively with GET routes (The read side can use a schema that is optimized for queries) as it is illustrated in the below diagram.
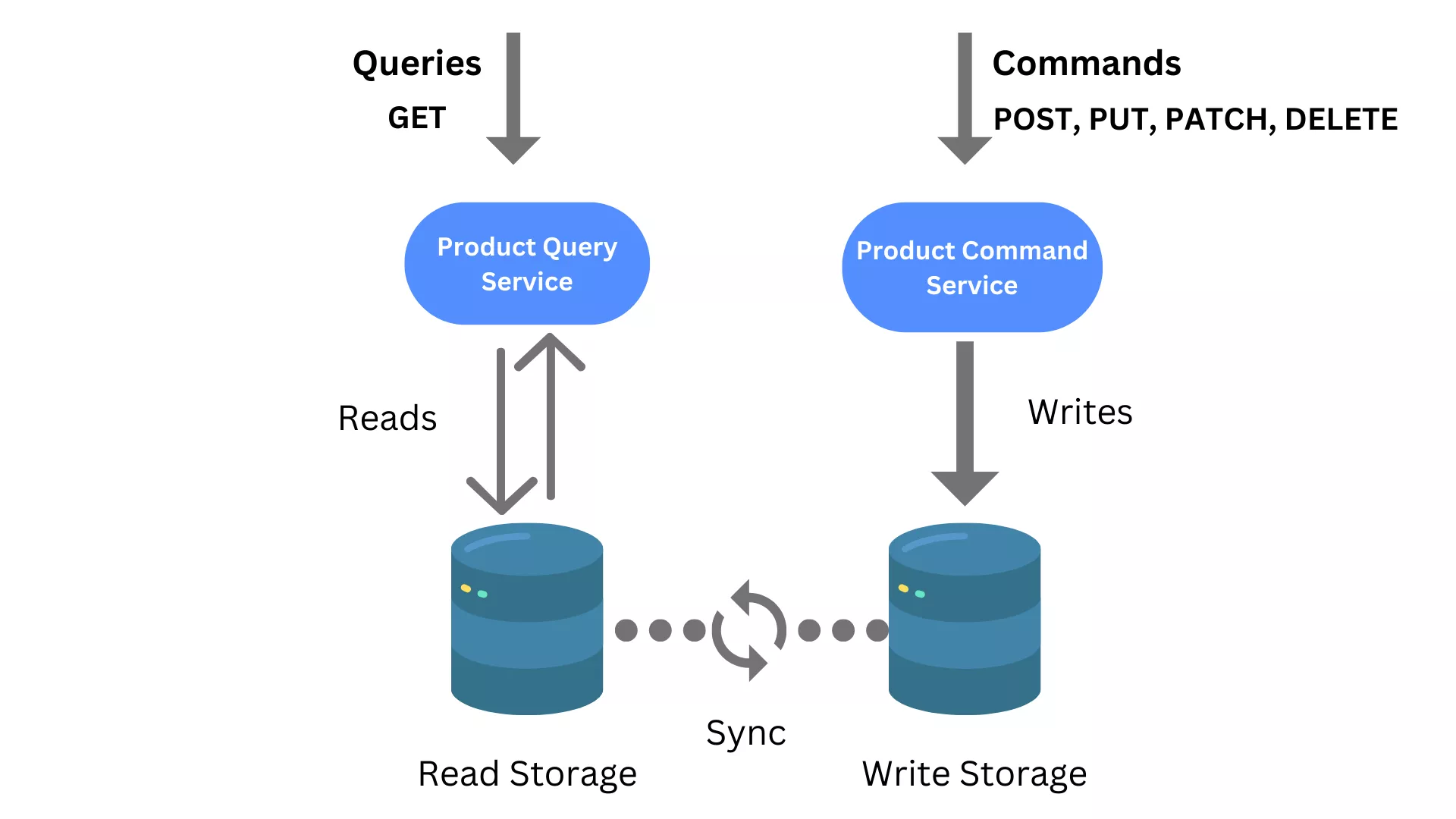
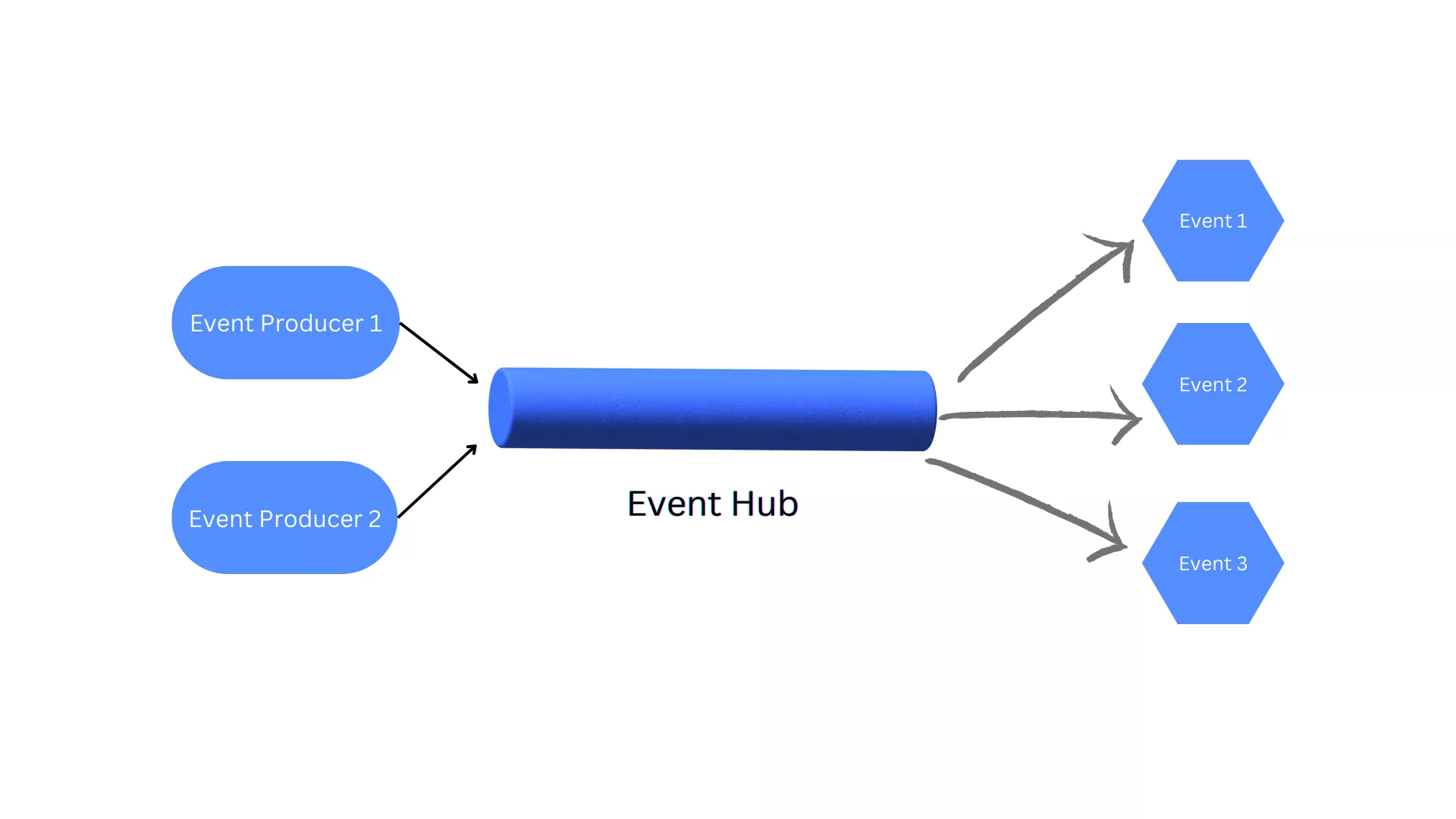
This pattern is typically combined with yet another event sourcing pattern, as it ensures that all changes made through Command API, are reflected in the read storage as well. The problem with the CQRS scenario, the read storage won't be immediately updated as part of one transaction (for example, as in the CRUD API service case because CRUD systems perform update operations directly against a data store). As a result, the query part will be not aware of the latest changes. Such a delay in storage reflecting the latest state of a resource is referred to as eventual consistency. The event sourcing pattern is very useful because it enables different systems to consume resource state changes as a series of events in the log via an Event Hub capability as you can see in the below diagram.
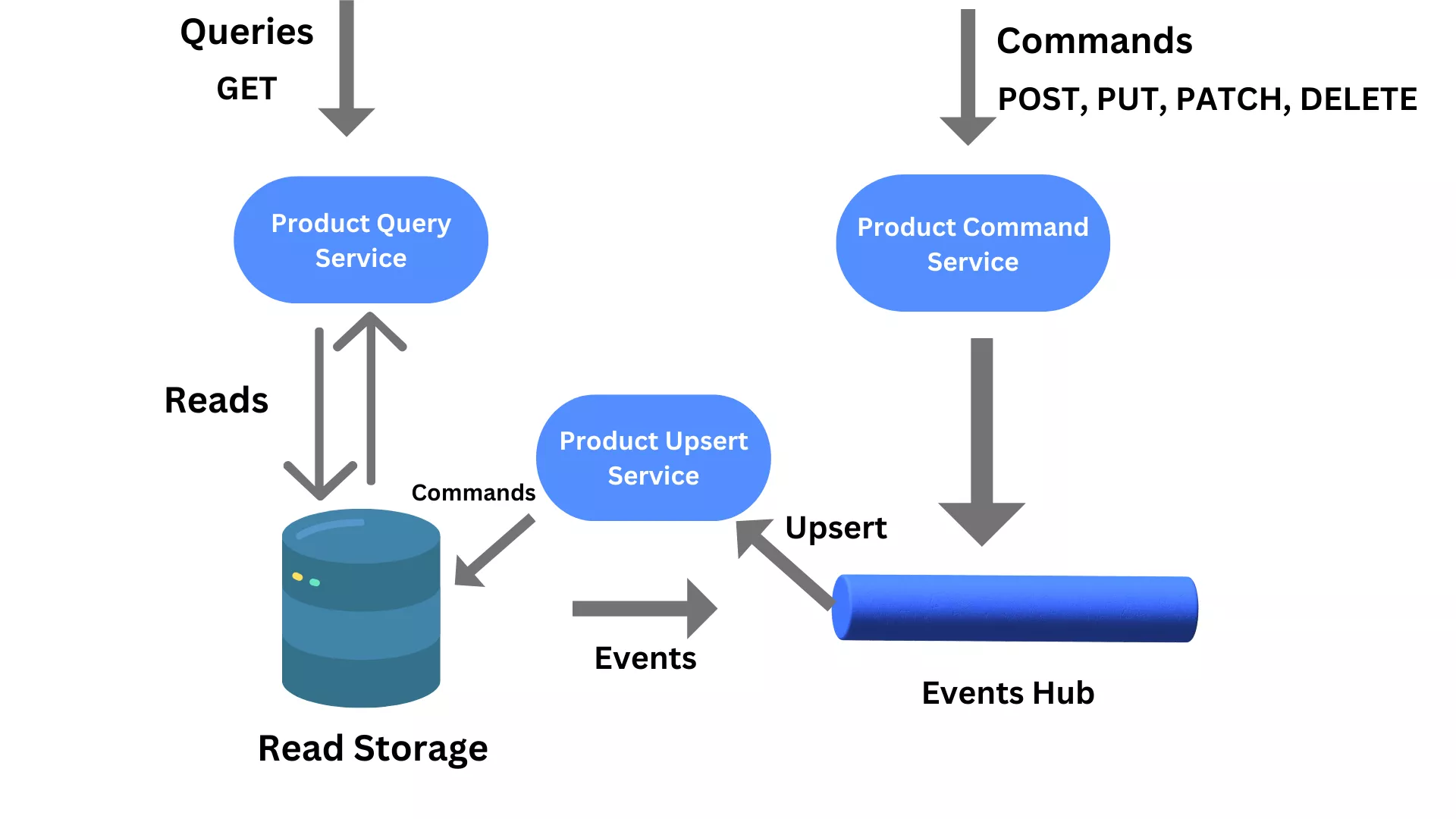
The diagram also shows the product's query operations performed against the read-only storage and the product's command operations persisted in an Event Hub capability. They are then picked up by another service called Upsert service responsible for upserting (create, update, and logical deletes) the read storage. Once an upsert action takes place, an event is generated that can be consumed by other services interested in any changes of state in product records.
API Gateway
Command and Query services APIs can be managed via lightweight, independently deployable, and scalable API gateways that can run anywhere that allow developers to manage API endpoints. They can handle extremely large volumes, as they run on highly scalable platforms, for example, Apache APISIX, Kong, Tyk, and Ambassador to name a few.
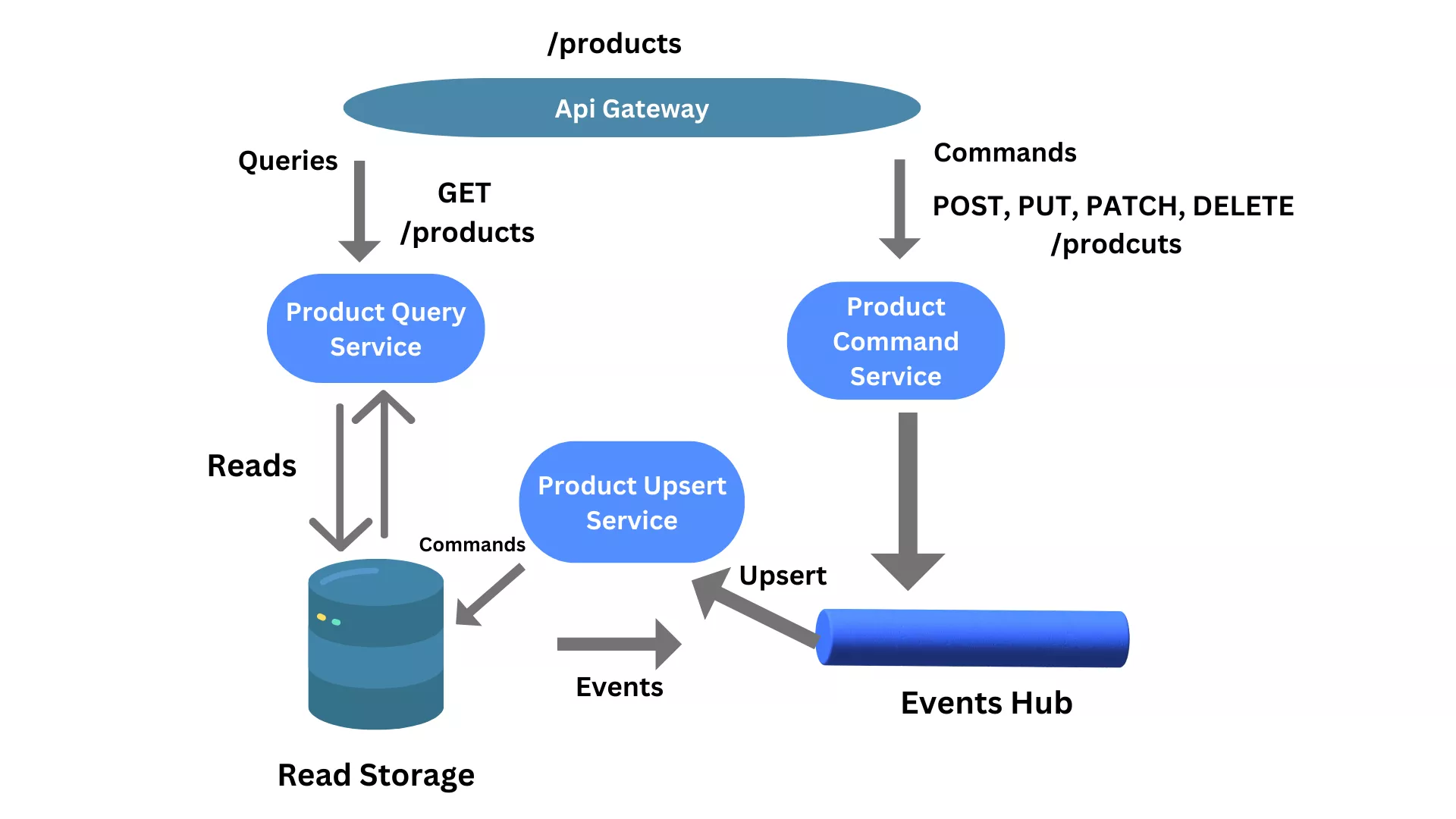
API Gateway can help with the challenges that you meet with implementing standard policies (for example, authorization, throttling, and rate limiting) for APIs. As an API Gateway acts as a central proxy to route all incoming requests from your clients to intended destinations (backend services).
You can utilize the API Gateway to expose a REST API in front of an event-driven integration. The below diagram illustrates the pattern first and foremost by showing how an API gateway implements resourcing routing to route read calls to the product's query service and upsert calls to the product's command service.
Serverless event processing
We can create our consumer services by using Serverless functions. Serverless is a popular event-driven architectural style that is rapidly gaining traction when building and operating cloud-native applications. Serverless platforms can be categorized into two broad categories, Function as a Service (FaaS) and Backend as a Service (BaaS). The FaaS method allows customers to build, deploy, run, and manage their applications without managing the underlying infrastructure. When events arrive at the Event Hub, a new serverless (a piece of code or a function) is triggered to handle the event as it is shown in the next diagram.
There are many FaaS providers in the market and each platform has unique scenarios in which it shines. The largest cloud companies (AWS, Azure, Google) provide solutions (AWS Lambda, Azure Functions, and Google Cloud Function respectively) that are meant to fit nearly every situation with generic cloud products.
Conclusion
The blog post demonstrated shortly how to build event-driven API services by using some well-known patterns that is flexible to change and more easily decomposed.
Despite some notable advantages the approach has, there are also some disadvantages as well. It increases the complexity of implementation, especially when compared with traditional CRUD services.
Since our example is based on traditional REST APIs all use HTTP as the transport and protocol layer, the situation is much more complex when it comes to event-driven APIs. However, the same approach can also be applied to multiple different protocols (for example, WebSockets, MQTT, or SSE) depending on the capabilities offered by the API gateway chosen (For example, Apache APISIX supports the proxy of gRPC Web protocol by means of its plug-in) how it handles conversions from one protocol to another.
Related resources
➔ What do you mean by “Event-Driven”?.
➔ Command Query Responsibility Segregation.
➔ API Gateway.
Recommended content
➔ Watch Video Tutorial:
➔ Read the blog posts:
Community⤵️
- 🙋 Join the Apache APISIX Community
- 🐦 Follow us on Twitter
- 📝 Find us on Slack
- 📧 Mail to us with your questions.