High Availability Configuration with TiDB and APISIX
On this page
- Project Background
- Apache APISIX Technical Architecture
- Limitations of etcd
- Project Motivation
- Project Introduction
- Solution Design
- Program Implementation
- Solution: the etcd adapter
- Future Plans
- Provide more configuration center options for Apache APISIX users
- Contribute to the architectural improvement of Apache APISIX Ingress Controller
- Donated to the Apache Foundation for incubation as an Apache APISIX subproject
In the TiDB Hackathon 2021, the APISIX team (team leader: Chao Zhang, team members: Zeping Bai, Zhengsong Tu, Jinghan Chen) presented the ability of TiDB to interface with Apache APISIX to implement a universal configuration center. In this article, we will bring you some stories behind the project and the future outlook, if you are interested in the project, please feel free to participate in the project.
Project Background
As an important component of microservices architecture, API gateway is the core entry/exit of traffic, used to unify and process business-related requests, which can effectively solve the problems of massive requests and malicious access, and ensure business security and stability.
As an open source cloud-native API gateway, Apache APISIX has three advantages: dynamic, real-time, and high-performance. It provides rich traffic management features such as load balancing, dynamic upstream, grayscale publishing, service fusion, authentication, and observability, helping enterprises to handle API and microservice traffic quickly and securely. Ingress and Service Grid scenarios.
Apache APISIX also supports high customization, Wasm support, and plugin written in Java, Go, Python, and other major computer languages.
Apache APISIX Technical Architecture
Apache APISIX adopts an architecture that separates the data plane from the control plane, receiving and distributing configurations through the configuration center so that the data plane is not affected by the control plane.
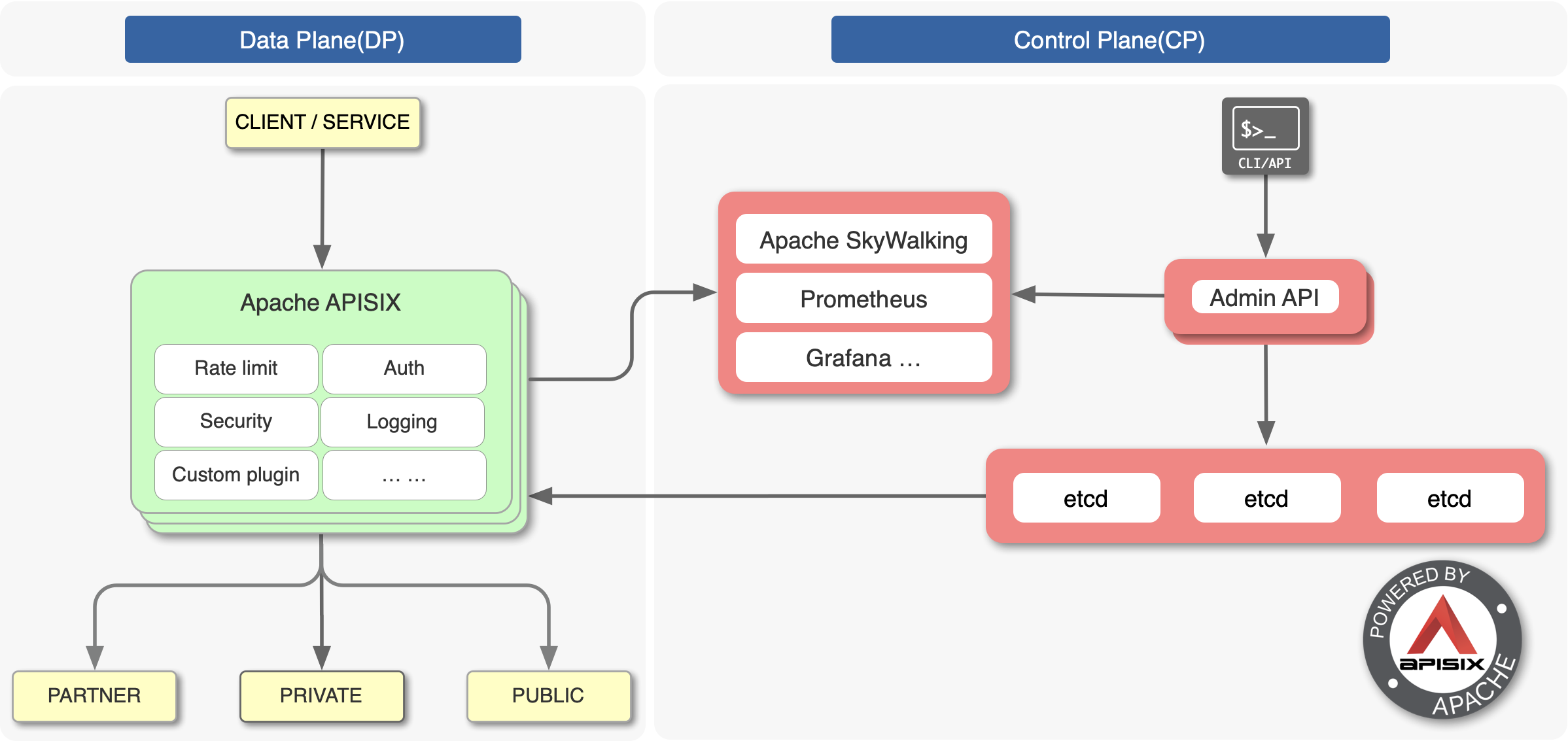
In this architecture, the data plane receives and processes caller requests and dynamically controls request traffic using Lua and NGINX, which can be used to manage the full lifecycle of API requests. The control plane contains the Manager API and the default configuration center etcd, which is used to manage the API gateways. When an administrator accesses and operates the console, the console calls the Manager API to send the configuration to etcd, which takes effect in real time on the gateway thanks to the etcd watch mechanism.
The default configuration center is etcd, which also supports Consul, Nacos, Eureka, etc. etcd naturally supports distributed, high availability, clustering, and has a lot of practice in K8s, etc. APISIX can easily support millisecond configuration updates, thousands of gateway nodes, and the gateway nodes are stateless and can be expanded and reduced at will.
Limitations of etcd
Architectural issues
First of all, etcd is based on BoltDB and has an upper limit. etcd’s default storage limit is 2 GB, and if the limit requires more than 2 GB, you can configure the storage with the -quota-backend-bytes flag, which can be adjusted up to 8 GB. An etcd cluster with 8 GB of storage is enough to serve one gateway, but if it serves N APISIX clusters at the same time, the capacity may not be enough. but if it serves N APISIX clusters at the same time, it may not have enough capacity and may cause some problems.
Secondly, etcd is essentially a CP system and cannot host a large number of client connections. Because etcd is distributed consensus through Raft, all read and write requests will be processed by the Leader of Raft, and a large number of client connections may lead to a high load on the whole cluster, which may affect the caller.
Scenario issues
In scenarios such as Ingress and Service Mesh, the use of etcd is relatively overloaded, and some users do not want to deploy components other than the control plane and data plane. For example, NGINX Ingress Controller can run with just one image, but APISIX Ingress Controller has an etcd in addition to the Ingress Controller control plane and APISIX data plane. For users, this technical architecture is more expensive to deploy, and they have to ensure the operation and maintenance of etcd.
K8s itself supports storage services, and all configuration information and Endpoints stored in the APISIX backend can be obtained from the K8s API Server. Using etcd in this scenario would make the whole selection more unwieldy.
The same is true for service grids. If you use APISIX in a Service Grid scenario and deploy etcd as well, the whole selection will be heavy. And in a service grid scenario, the number of Pods can be hundreds or even tens of thousands, which is very common. If all the tens of thousands of Pods are connected to etcd, etcd will become the bottleneck of the whole service.
Cost issues
First, etcd has high operation and maintenance costs, and some companies do not have dedicated etcd operation and maintenance engineers. At least 3-5 instances are needed to deploy etcd, and after etcd is running successfully, data backups and snapshots need to be done regularly. In order to monitor the operation of etcd and understand the health of etcd in real time, you also need to build an observable system to provide the necessary alerting support. If a company does not have dedicated etcd operations and maintenance engineers, it may not be able to do a good job of etcd operations and maintenance.
Second, some companies or organizations have long-standing middleware or infrastructure, and switching configuration centers can be costly. For these companies or organizations, they often prefer to reuse existing middleware or infrastructure as the configuration center of APISIX, such as TiDB, Consul, and Apache ZooKeeper, so as to converge the technology stack and avoid additional costs.
Project Motivation
Based on the above considerations, we decided to research a new solution to change the current overloaded technical architecture, provide more flexible options for Apache APISIX users, not bound by etcd, relieve the pressure of etcd operation and maintenance for existing users, reduce operation and maintenance costs, and at the same time expect to give users more and better choices, break through the bottleneck of etcd itself.
Unbinding APISIX from etcd gives users more and more flexible choices, which is actually the charm of open source. If we can remove this layer of restriction and not limit how users can use it, they may create more surprises.
Project Introduction
Solution Design
How to decouple APISIX and etcd?
The first issue we considered at the beginning of the project design was how to decouple APISIX from etcd, because APISIX’s careful code and data structures are closely related to etcd. The Admin API, which is responsible for manipulating the configuration, usually includes the metadata of etcd in the return value.
For example, etcd v3’s Revision, etcd v2’s createdIndex, modifiedIndex, and even in APISIX’s core logic, a route or an Upstream object will carry this metadata.
It would be prohibitively expensive to fundamentally transform APISIX. Modifying such a core area may also affect the existing stability of APISIX, so directly modifying APISIX may not be a good solution.
Introducing an additional middle layer
If direct transformation is too costly and risky, can we not consider introducing an extra layer of middle layer? There is a famous saying in the computer world - “there is no problem that cannot be solved by adding a layer”. If we were to add a layer, what specific things would this layer be responsible for? What are the things to be done? To summarize, this layer needs to accomplish two more important things.
First, this additional middle tier needs to provide the etcd v3 API and support the etcd gRPC Gateway; currently, APISIX only supports etcd v3. For APISIX, this middle tier is still an etcd, and it must provide the etcd v3 API. Gateway, because APISIX still interacts with etcd via HTTP protocol, and the etcd v3 API is based on gRPC, we need etcd’s gRPC Gateway to convert HTTP requests into gRPC requests, so that the whole interaction can proceed smoothly.
Second, this extra middle layer can interface with different storage solutions. We need to figure out how to support TiDB, PostgreSQL, SQLite, and even Consul and Apachce ZooKeeper.
Only when these two things are done can this middle tier interface to different storage solutions and thus bring the full configuration center functionality to APISIX.
Program Implementation
Once we have this middle tier, how do we integrate TiDB? We actually have a similar project to look at. Although K8s natively supports etcd as a storage solution, Rancher’s K3s project doesn’t use etcd, probably because if K3s is deployed in some embedded environment, etcd has some limitations that make it not well maintained. So, Rancher supports additional components such as PostgreSQL, MySQL, SQLite, and Dqlite through the Kine project, giving K3s users the flexibility to choose other storage options. To summarize, Kine project has the following points that we should learn from.
First, TiDB is compatible with MySQL, and Kine project itself supports MySQL, so we can borrow or refer to some implementations of Kine to help our project better support and interface with TiDB.
Second, Kine completely implements the watch function that etcd needs to support. Because APISIX is based on push mode to sense configuration changes, the latency of configuration changes is usually in millisecond level, which is very low. The watch mechanism is very important because it involves pushing the configuration.
Third, Kine also emulates the MVCC feature of etcd to support Compact, where each change, write, update or delete is a row of data in Kine or TiDB. The primary key for each row of data is etcd’s Revision, which is a counter that keeps track of the number of recent changes. In this way, Kine implements multi-version support.
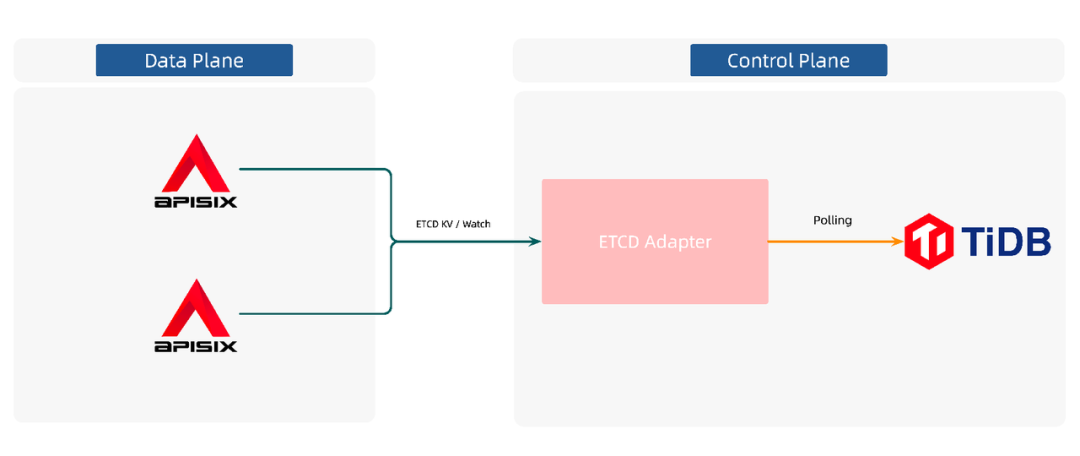
By introducing a similar architecture, Apache APISIX does not have to interact with the real storage center, but with this intermediate layer. As shown above, the APISIX and etcd adapter middle tier goes through etcd’s KV API and Watch API. etcd adapter polls TiDB, senses configuration writes, completes the watch operation, and thus pushes the data to APISIX.
Solution: the etcd adapter
With these thoughts and the reference of the Kine project, we have developed the etcd adapter project on the shoulders of giants.
First of all, this project supports TiDB, MySQL and In-Memory B-Tree configuration centers, and soon SQLite and PostgreSQL. If you choose the In-Memory B-tree option, you can directly embed the etcd adapter into the target application. This way there is one less component, which can further improve the overall user experience.
Second, the project supports the etcd v3 API, which currently supports only a subset of the APIs required by APISIX, such as the KV API and the Watch API, while other types of APIs, such as Lease and authentication-based APIs, are not yet fully implemented.
Finally, the project supports the gRPC Gateway, which translates the corresponding gRPC interface into the corresponding Restful interface for APISIX to call.
Although we put the etcd adapter on the control plane, we can also put it on the side of each APISIX as a sidecar. Each of the two options has its own benefits, so you can choose flexibly according to your actual situation.
Future Plans
We have the following ideas to share with you about the follow-up plan and future direction of this project.
Provide more configuration center options for Apache APISIX users
We hope that the etcd adapter project will give Apache APISIX users more choices of configuration centers, so that they will not be locked by etcd and can choose solutions according to their actual situation. Consul KV is also based on Raft and has high availability. In addition, you can also consider the more mainstream Apollo or Apache ZooKeeper, which is the counterpart of etcd, and PostgreSQL or other alternatives
Contribute to the architectural improvement of Apache APISIX Ingress Controller
We hope that the etcd adapter project will help improve the architecture of APISIX Ingress Controller. etcd adapter supports In-Memory B-Tree, which embeds data into memory without the need for physical storage.
In this way, the etcd adapter can become part of the APISIX Ingress Controller, and the Apache Ingress Controller only needs to keep the Ingress Controller control plane and the APISIX data plane components. Since there is no etcd, APISIX can even interact directly with the Ingress Controller to get configuration change data.
In addition, we can also put the Ingress Controller control plane and APISIX data plane in the same image, so that the control plane and data plane can be deployed as one. In the end, we only need one command and one image to run APISIX Ingress Controller in K8s target cluster. If the control plane and data plane are put together, people don’t need to deploy an additional etcd and a control plane, which is equivalent to two less components directly and can greatly improve the user experience.
Donated to the Apache Foundation for incubation as an Apache APISIX subproject
Currently, this project is sitting in the API7.ai repository. In the future, we hope to continue to polish this project, and when it has been iteratively improved, we will donate it to the Apache Software Foundation to incubate it as a sub-project of Apache APISIX, so as to attract more people from the community to improve this project with us and make the Apache APISIX ecosystem even bigger.
